Page: 1
/ 14
Total 401 questions
Google Cloud Certified Professional Data Engineer Exam Questions
Question 1
You are administering shared BigQuery datasets that contain views used by multiple teams in your organization. The marketing team is concerned about the variability of their monthly BigQuery analytics spend using the on-demand billing model. You need to help the marketing team establish a consistent BigQuery analytics spend each month. What should you do?
Answer : B
To help the marketing team establish a consistent BigQuery analytics spend each month, you can use BigQuery reservations to allocate dedicated slots for their queries. This provides predictable costs by reserving a fixed amount of compute resources.
BigQuery Reservations:
BigQuery Reservations allow you to purchase dedicated query processing capacity in the form of slots.
By reserving slots, you can control costs and ensure that the marketing team has the necessary resources for their queries without unexpected increases in spending.
Baseline Slots:
Setting a baseline of 500 slots without autoscaling ensures a consistent allocation of resources.
This provides a predictable monthly cost, as the marketing team will be billed for the reserved slots regardless of actual usage.
Billing Back:
The marketing team's usage can be billed back based on the fixed reservation cost, ensuring budget predictability.
This approach avoids the variability associated with on-demand billing, where costs can fluctuate based on query volume and complexity.
No Autoscaling:
By not enabling autoscaling, you prevent additional costs from being incurred due to temporary increases in query demand.
This fixed reservation ensures that the marketing team only uses the allocated 500 slots, maintaining a consistent monthly spend.
Google Data Engineer Reference:
BigQuery Reservations Documentation
BigQuery Slot Reservations
Managing BigQuery Costs
Using a fixed reservation of 500 slots provides the marketing team with predictable costs and the necessary resources for their queries without unexpected billing variability.
Question 2
As your organization expands its usage of GCP, many teams have started to create their own projects. Projects are further multiplied to accommodate different stages of deployments and target audiences. Each project requires unique access control configurations. The central IT team needs to have access to all projects. Furthermore, data from Cloud Storage buckets and BigQuery datasets must be shared for use in other projects in an ad hoc way. You want to simplify access control management by minimizing the number of policies. Which two steps should you take? Choose 2 answers.
Answer : A, C
Question 3
You want to use a database of information about tissue samples to classify future tissue samples as either normal or mutated. You are evaluating an unsupervised anomaly detection method for classifying the tissue samples. Which two characteristic support this method? (Choose two.)
Answer : A, D
Unsupervised anomaly detection techniques detect anomalies in an unlabeled test data set under the assumption that the majority of the instances in the data set are normal by looking for instances that seem to fit least to the remainder of the data set.https://en.wikipedia.org/wiki/Anomaly_detection
Question 4
Your startup has never implemented a formal security policy. Currently, everyone in the company has access to the datasets stored in Google BigQuery. Teams have freedom to use the service as they see fit, and they have not documented their use cases. You have been asked to secure the data warehouse. You need to discover what everyone is doing. What should you do first?
Answer : A
Question 5
You have some data, which is shown in the graphic below. The two dimensions are X and Y, and the shade of each dot represents what class it is. You want to classify this data accurately using a linear algorithm.
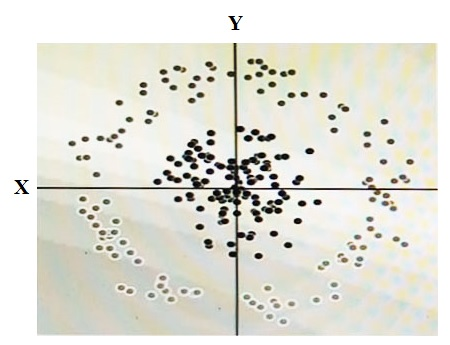
To do this you need to add a synthetic feature. What should the value of that feature be?
Answer : D
Question 6
Your team has created several BigQuery curated datasets containing anonymized industry benchmark data. You want to make these datasets easily discoverable and accessible for querying by external partner companies within their own Google Cloud projects. You need a secure and scalable solution. What should you do?
Answer : B
Analytics Hub (part of BigQuery sharing) is the enterprise-grade, Google-recommended way to share data across organizational boundaries.
Discoverability: Analytics Hub provides a central portal where partners can search for and 'subscribe' to datasets. Traditional IAM grants (A) do not provide a discovery interface.
Scalability: You can publish a single 'listing' and allow many partners to subscribe to it. Each subscriber gets a 'linked dataset' in their project.
Security & Governance: The publisher retains control. You can see who has subscribed and even enforce 'data egress' controls to prevent partners from copying or exporting the data while still allowing them to query it.
Correcting other options:
A: This works for a few users but lacks the metadata, searchability, and formal 'subscription' lifecycle of Analytics Hub.
C: Authorized views are for internal security within a project/org and don't solve the cross-org discovery problem.
D: Exporting data creates data silos, increases storage costs, and loses the real-time query benefits of BigQuery.
'Analytics Hub is a data exchange platform that lets you share data and insights at scale across organizational boundaries... Listings let you share data without replicating the shared data... Subscribers discover data through the exchange and create a linked dataset in their own project to query the data.' (Source: Introduction to BigQuery sharing)
Question 7
Cloud Dataproc charges you only for what you really use with _____ billing.
Answer : B
One of the advantages of Cloud Dataproc is its low cost. Dataproc charges for what you really use with minute-by-minute billing and a low, ten-minute-minimum billing period.