Page: 1
/ 14
Total 330 questions
Amazon AWS Certified Machine Learning - Specialty MLS-C01 AWS ML Specialty Exam Questions
Question 1
[Exploratory Data Analysis]
A machine learning (ML) specialist must develop a classification model for a financial services company. A domain expert provides the dataset, which is tabular with 10,000 rows and 1,020 features. During exploratory data analysis, the specialist finds no missing values and a small percentage of duplicate rows. There are correlation scores of > 0.9 for 200 feature pairs. The mean value of each feature is similar to its 50th percentile.
Which feature engineering strategy should the ML specialist use with Amazon SageMaker?
Answer : A
Question 2
[Machine Learning Implementation and Operations]
A city wants to monitor its air quality to address the consequences of air pollution A Machine Learning Specialist needs to forecast the air quality in parts per million of contaminates for the next 2 days in the city as this is a prototype, only daily data from the last year is available
Which model is MOST likely to provide the best results in Amazon SageMaker?
Answer : A
Question 3
[Data Engineering]
A company wants to predict stock market price trends. The company stores stock market data each business day in Amazon S3 in Apache Parquet format. The company stores 20 GB of data each day for each stock code.
A data engineer must use Apache Spark to perform batch preprocessing data transformations quickly so the company can complete prediction jobs before the stock market opens the next day. The company plans to track more stock market codes and needs a way to scale the preprocessing data transformations.
Which AWS service or feature will meet these requirements with the LEAST development effort over time?
Answer : A
Question 4
[Modeling]
The displayed graph is from a foresting model for testing a time series.
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
Answer : D
Question 5
[Modeling]
Given the following confusion matrix for a movie classification model, what is the true class frequency for Romance and the predicted class frequency for Adventure?
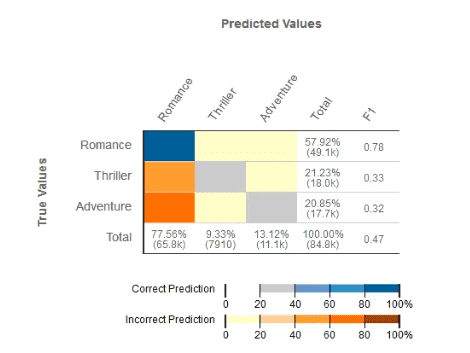
Answer : B
Question 6
[Modeling]
A Machine Learning Specialist observes several performance problems with the training portion of a machine learning solution on Amazon SageMaker The solution uses a large training dataset 2 TB in size and is using the SageMaker k-means algorithm The observed issues include the unacceptable length of time it takes before the training job launches and poor I/O throughput while training the model
What should the Specialist do to address the performance issues with the current solution?
Answer : C
Question 7
[Data Engineering]
A pharmaceutical company performs periodic audits of clinical trial sites to quickly resolve critical findings. The company stores audit documents in text format. Auditors have requested help from a data science team to quickly analyze the documents. The auditors need to discover the 10 main topics within the documents to prioritize and distribute the review work among the auditing team members. Documents that describe adverse events must receive the highest priority.
A data scientist will use statistical modeling to discover abstract topics and to provide a list of the top words for each category to help the auditors assess the relevance of the topic.
Which algorithms are best suited to this scenario? (Choose two.)
Answer : A, C