Page: 1
/ 14
Total 68 questions
Cisco Designing and Implementing Enterprise Network Assurance 300-445 ENNA Exam Questions
Question 1
ThousandEyes offers several native integrations for receiving instant event notifications triggered by alerts. Which of the following integrations are available directly within the ThousandEyes platform? Select all that apply.
Answer : A, B, C, D, F, G, H
According to the Designing and Implementing Enterprise Network Assurance (300-445 ENNA) architecture, ThousandEyes provides a suite of native, 'out-of-the-box' integrations specifically designed for alert notifications. These integrations are configured via the Manage > Integrations or Alert Rules > Notifications tabs and allow the platform to push instant event data to a variety of collaboration, IT operations, and observability tools.
The verified list of native notification integrations includes:
ServiceNow (A): Facilitates direct incident management and automated ticketing workflows.
PagerDuty (B): Allows for automated incident escalation and on-call routing based on ThousandEyes alerts.
MS Teams (C) & Slack (H): Enable real-time chatops by pushing alert details and permalinks directly into specified channels for team collaboration.
Splunk (D): Utilizes the Cisco ThousandEyes App for Splunk to ingest alert data for historical analysis and correlation within a SIEM or logging platform.
AppDynamics (F): Sends alert notifications directly into an AppDynamics instance, allowing application owners to correlate network issues with APM metrics.12
Webex (G): Integrates with the Webex Control Hub and specific Webex spaces to provide unified visibility for collaboration performance.34
AWS (Option E) is not a native alert notification destination 5in this context; instead, ThousandEyes integrates with AWS for 'Cloud Insights' (ingesting VPC Flow Logs) and 'Test Recommendations' rather than acting as a receiver for event notifications like a chat or ITSM tool. By utilizing these native integrations, enterprise teams ensure that the right stakeholders are notified through their preferred communication channels the moment a performance threshold is breached, drastically improving response times across the organization.
Question 2
You have been tasked with creating a dashboard in your organization's Observability platform. This dashboard should have data that is streamed in real-time and used to populate data for tables, graphs, charts, and other formats. What kind of integration should you use?
Answer : B
Within the Designing and Implementing Enterprise Network Assurance (300-445 ENNA) framework, the transition from 'polling' to 'streaming' is a major architectural shift. To populate real-time dashboards in external observability platforms like Grafana, Splunk, or AppDynamics, the architect should utilize the OpenTelemetry (OTel) integration (Option B).
ThousandEyes for OpenTelemetry is a push-based API built on the standardized OpenTelemetry Protocol (OTLP). Unlike traditional REST API polling (Option A), which retrieves data at fixed intervals and can be subject to rate limiting and latency, the OTel integration allows ThousandEyes to stream granular network metrics as they are collected. These metrics---including latency, loss, jitter, and HTTP response times---are exported in a standardized format that is natively understood by modern observability backends. This allows the platform to populate complex visualizations such as time-series graphs, heatmaps, and multi-metric tables in near real-time, providing a 'single pane of glass' view that correlates network performance with application and infrastructure telemetry.
A key advantage of the OTel approach is data portability and correlation. By applying metadata tags to ThousandEyes tests, the data can be filtered and categorized within the external dashboard to match the organization's business logic (e.g., grouping by region or application tier). This enables SREs and NetOps teams to quickly identify if a performance dip in an application dashboard correlates with a spike in internet latency measured by ThousandEyes. Options C and D do not provide the streaming data pipeline required for real-time external dashboard population. Thus, OpenTelemetry is the definitive choice for high-fidelity, real-time observability integration.
Question 3
Your organization wants to be notified of an event as soon as it is triggered by an alert threshold. This notification should be sent to your ITSM and generate an incident so it can be responded to appropriately. What kind of integration should you use?
Answer : A
In the Designing and Implementing Enterprise Network Assurance (300-445 ENNA) curriculum, the objective of modern network assurance is to bridge the gap between 'visibility' and 'action'. When an organization requires an automated workflow to handle network performance anomalies, the most efficient architecture is the native ServiceNow Integration (Option A). This integration is categorized as a 'Custom-Built' or native integration within the ThousandEyes platform, designed specifically to facilitate the delivery of direct notifications into a ServiceNow account.
According to the ENNA implementation standards, the ThousandEyes ServiceNow integration utilizes the ServiceNow Incident Management module. When a predefined alert rule (such as a 5% packet loss threshold on a critical SaaS path) is violated, ThousandEyes triggers an event and immediately pushes the alert data to ServiceNow via an OAuth-authenticated connection. Within ServiceNow, this data is used to automatically generate an Incident, complete with relevant metadata such as the test name, agent location, and the specific metrics that triggered the violation. This automation eliminates the manual overhead of 'copy-pasting' alert details from a monitoring dashboard into a ticketing system, thereby significantly reducing the Mean Time to Identification (MTTI).
While Custom Webhooks (Option C) can achieve a similar result by sending JSON payloads to a REST API, they require additional development effort to parse the data on the receiver side. The native ServiceNow integration provides a pre-configured template that maps ThousandEyes alert fields directly to ServiceNow incident fields, offering a 'one-click' setup experience that is preferred for enterprise-grade deployments. Options B and D are irrelevant for the specific goal of ITSM incident generation. Therefore, for direct ITSM notification and incident creation, the native ServiceNow Integration is the verified recommendation.
Question 4
Review the exhibits. Based on the evidence, which action is most likely to solve the issue?

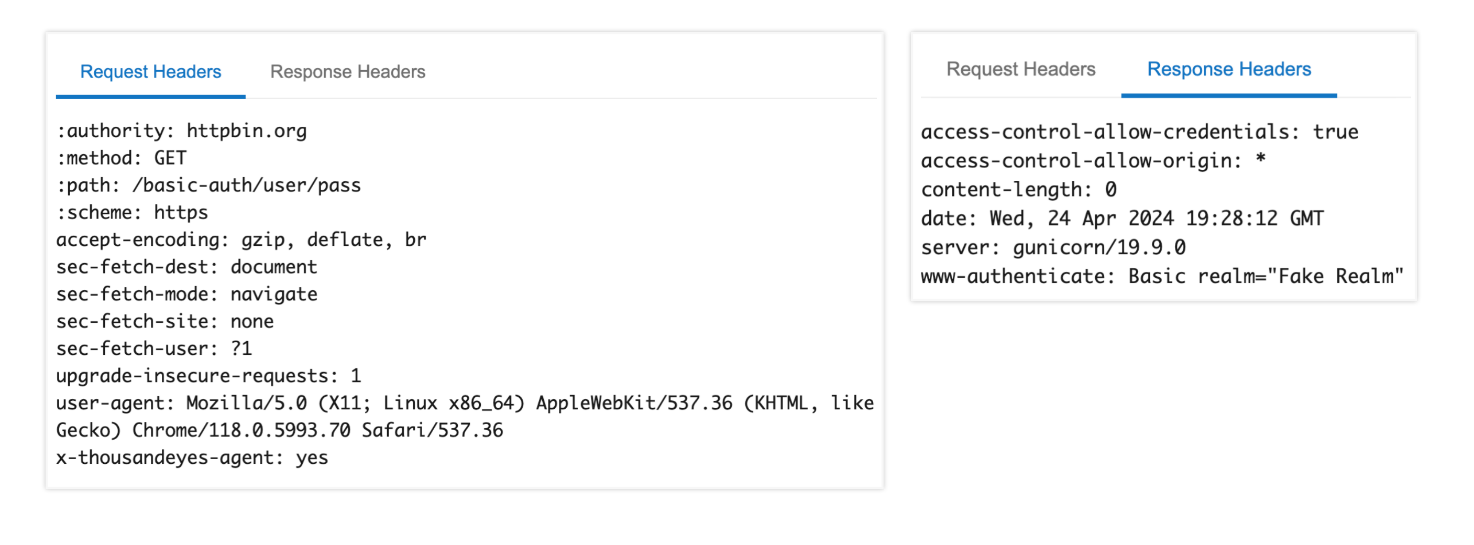
Answer : B
Question 5
Refer to the exhibit.
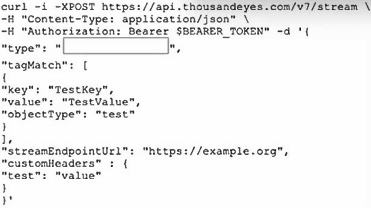
Which integration type should be configured between ThousandEyes and Grafana?
Answer : A
In the Designing and Implementing Enterprise Network Assurance (300-445 ENNA) curriculum, the evolution of network monitoring includes moving from periodic polling to real-time data streaming. The exhibit displays a curl command targeting the ThousandEyes API v7 /stream endpoint. When integrating ThousandEyes with high-performance observability platforms like Grafana, the standardized and recommended method for machine-to-machine data exchange is through OpenTelemetry (OTel).
According to the ENNA architecture guidelines, the ThousandEyes Streaming API allows users to push granular test metrics (such as network latency, packet loss, and jitter) to external collectors in an OTel-compatible format. In the provided JSON payload, the 'type' field is a mandatory parameter that defines the integration protocol. For Grafana, which natively supports OpenTelemetry Protocol (OTLP) via its OpenTelemetry Collector, the value must be set to 'opentelemetry' (Option A). This tells the ThousandEyes streaming engine to encapsulate the data according to the OTel semantic conventions, ensuring that Grafana can correctly interpret and visualize the metrics without additional custom parsing logic.
While other options exist in the ThousandEyes ecosystem, they do not fit the specific API call shown for this use case:
Custom Webhooks (Option B) are typically used for event-driven alerts and notifications (e.g., sending a POST request when a threshold is breached) rather than continuous high-fidelity metric streaming.
Push-api and poll-api (Options C and D) are not valid 'type' values within the context of the v7 /stream endpoint, as the streaming service specifically utilizes the OpenTelemetry framework for real-time delivery.
By selecting opentelemetry, the network engineer enables a robust 'push-based' integration that provides real-time visibility into application performance and network health, leveraging Grafana's advanced dashboarding capabilities to analyze ThousandEyes telemetry data alongside other enterprise infrastructure metrics.
Introduction to ThousandEyes for OpenTelemetry
This video provides a foundational understanding of how ThousandEyes uses modern streaming frameworks to export critical performance data to external observability platforms.
Question 6
Refer to the exhibits.
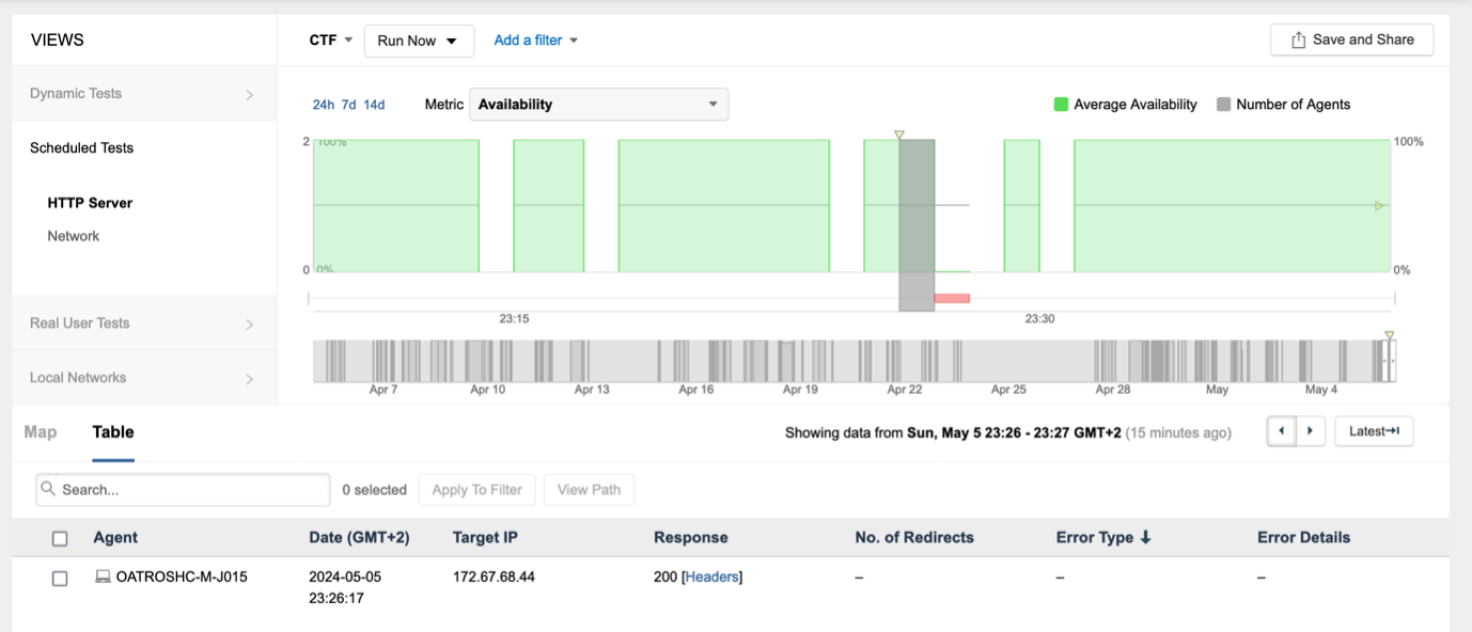
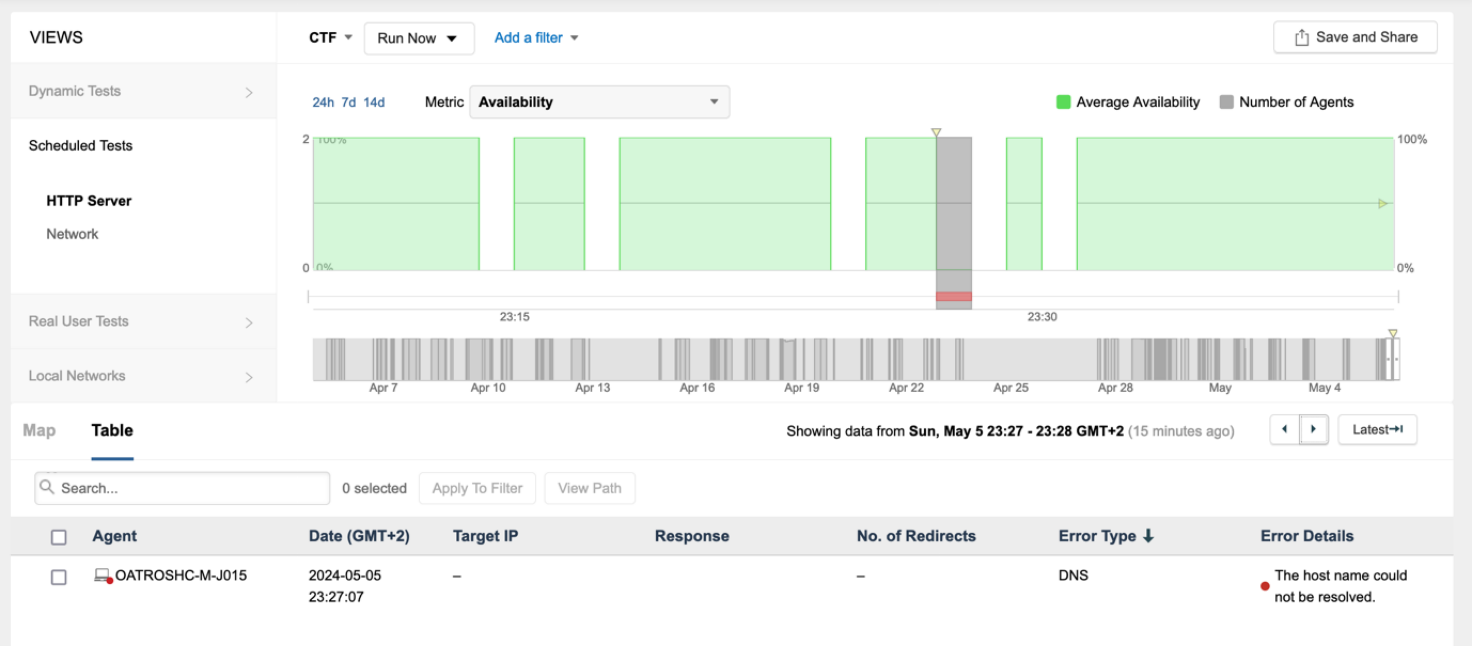
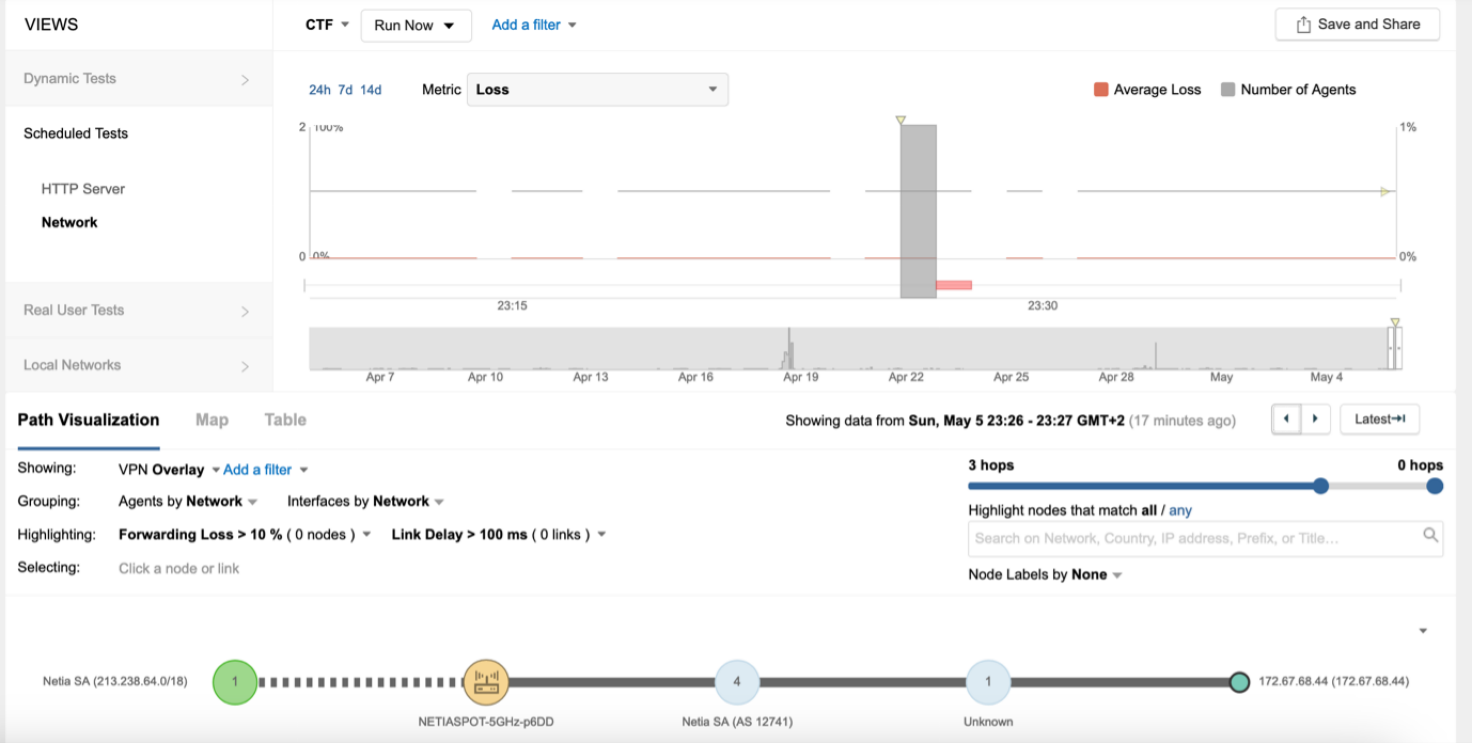
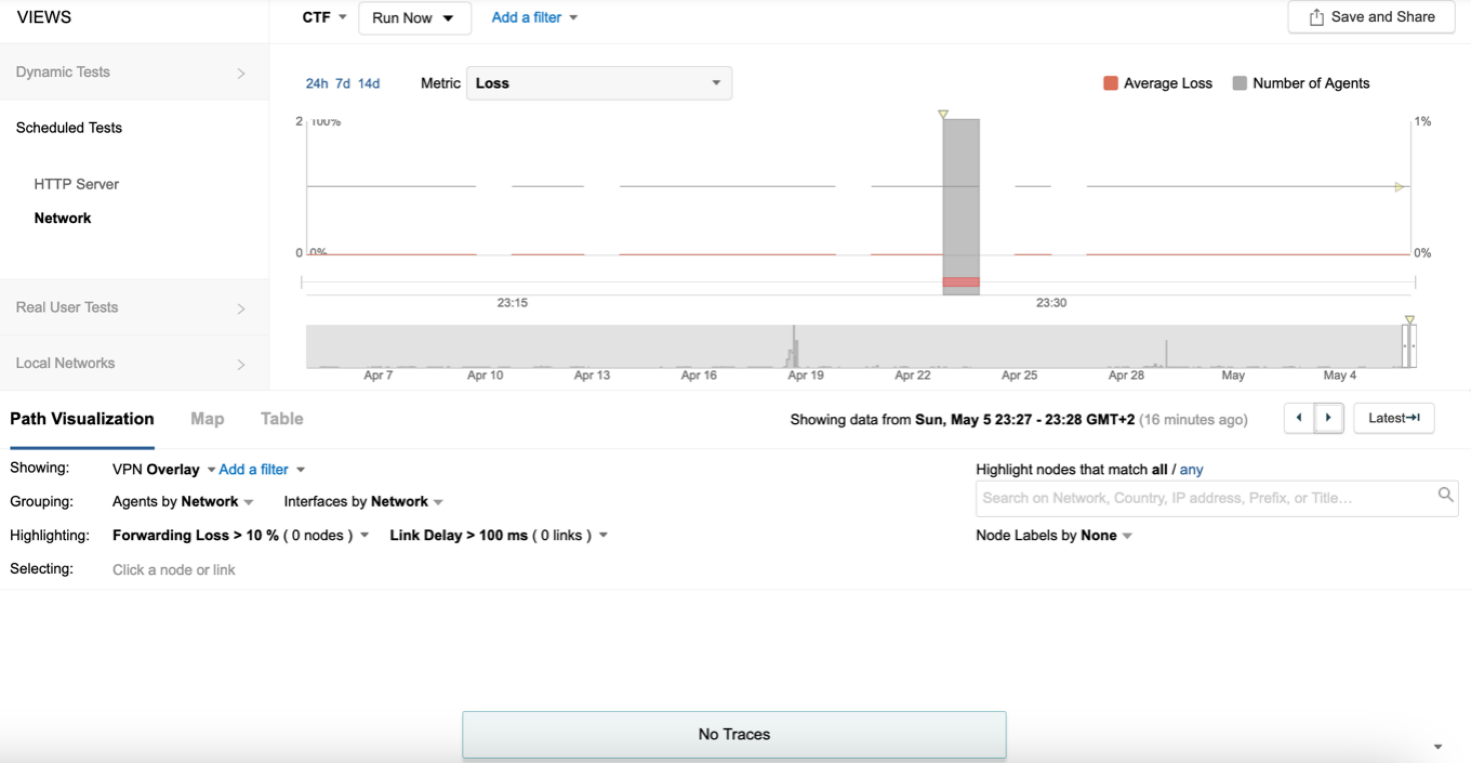
The endpoint has the following IP credentials:
192.168.100.9/24, DNS: 8.8.8.8, 8.8.4.4, GW: 192.168.100.1
Based on the views presented in the exhibits, what led to the error occurring on Sun, May 5 23:27 GMT +2?
Answer : C
Question 7
An architect needs to analyze network path metrics from their internal network, specifically from the access layer to a cloud-hosted web server.1 Which ThousandEyes agent is most appropriate for this task?
Answer : B
In the framework of Designing and Implementing En8terprise Network Assurance (300-445 ENNA), selecting the correct agent type depends heavily on the vantage point required for the specific observation. For this scenario, the architect must collect metrics from the internal network access layer---the point closest to where the users or devices reside within the corporate perimeter---towards a cloud-hosted destination.
The Enterprise Agent (Option B) is the most appropriate choice because it is specifically designed to be deployed on infrastructure owned and managed by the organization. These agents are 'inside-out' vantage points that can be installed directly on Cisco Catalyst 9300 or 9400 Series switches at the access layer using Docker containers. By deploying an Enterprise Agent at the access layer, the architect gains visibility into the entire network path, starting from the internal LAN, traversing the edge/WAN, and reaching into the cloud-hosted web server. This allows for the identification of issues such as local congestion, ISP peering problems, or cloud provider latency.
Other options do not meet the criteria:
Synthetic Agent (Option A): This is a distractor term. All ThousandEyes agents (Cloud, Enterprise, and Endpoint) are synthetic agents because they all perform active synthetic testing.
Cloud Agent (Option C): These are pre-deployed by Cisco in global ISP data centers and provide an 'outside-in' view.14 While useful for monitoring public-facing availability, they cannot provide visibility into the internal network or the access layer of the organization.
Endpoint Agent (Option D): While these are installed on end-user machines and provide a 'user-centric' view, they are generally not used for infrastructure-level path analysis from the access layer switches themselves.
Thus, the Enterprise Agent is the definitive choice for monitoring from the access layer to the cloud.