Page: 1
/ 14
Total 126 questions
CompTIA SecAI+ v1 Exam CY0-001 Practice Questions
Question 1
A user interface engineer adds new graphics to the latest release of an AI-integrated application. During the update, the engineer accidentally causes the model to retrain on unverified dat
a. After the update, the model begins to return many errors.
Which of the following is the best way to mitigate future errors?
Answer : C
Basic Concept: When a non-ML engineer can accidentally trigger model retraining during a UI update, this indicates a lack of proper lifecycle management and change controls around the AI model. Uncontrolled retraining on unverified data is a critical vulnerability in the development and deployment process. CompTIA SecAI+ Study Guide identifies the Model Development Life Cycle as the framework for preventing such issues.
Why C is Correct: Implementing a Model Development Life Cycle (MDLC) establishes formal, controlled processes for every stage of model development and updates including data validation requirements before training, change management gates, testing and validation stages, and separation of duties between UI development and model training activities. An MDLC would have prevented the accidental retraining by requiring explicit, controlled authorization before any model training occurs.
Why A is Wrong: A WAF filters HTTP traffic at the application boundary. It does not govern internal development processes or control when and how model retraining occurs within the AI development pipeline.
Why B is Wrong: Role-based access control can restrict who has permission to trigger model retraining, which would help prevent this specific incident. However, it is one component of a broader MDLC governance framework and does not address data validation, testing stages, or the complete change management process.
Why D is Wrong: A GAN is a model architecture for generating synthetic data. It is a training technique unrelated to lifecycle governance or preventing accidental retraining from unverified data during unrelated application updates.
Question 2
An organization recently developed an AI-powered product and discovers that it is vulnerable to attacks in which malicious actors can alter the input, causing the system to recommend inappropriate information.
Which of the following techniques is the most effective way to secure the system against manipulation attacks?
Answer : D
Basic Concept: Input manipulation attacks --- including adversarial examples and prompt injection --- alter inputs to cause AI systems to produce unintended, harmful, or inappropriate outputs. Defending against these attacks requires mechanisms that validate and constrain both inputs and outputs at runtime. CompTIA SecAI+ Study Guide identifies guardrails as the primary defense against input manipulation in AI systems.
Why D is Correct: Guardrails implement real-time validation and filtering of both incoming inputs and outgoing recommendations. They detect manipulated inputs that deviate from expected patterns, enforce content policies on outputs, and prevent the system from producing inappropriate recommendations regardless of how cleverly the input was crafted. Guardrails provide the most comprehensive and directly applicable defense against the described manipulation attack scenario.
Why A is Wrong: Cross-validation is a model evaluation technique that assesses how well a model generalizes to independent datasets during training. It measures predictive performance but does not provide runtime protection against input manipulation attacks on a deployed system.
Why B is Wrong: Feature regularization is a training technique that adds penalties to model weights to prevent overfitting. It improves generalization during training but does not inspect or validate inputs at inference time to detect manipulation.
Why C is Wrong: Feature scaling normalizes input feature values to a standard range for training efficiency. Like regularization, it is a preprocessing and training step that has no effect on defending against runtime input manipulation attacks on deployed systems.
Question 3
SIMULATION
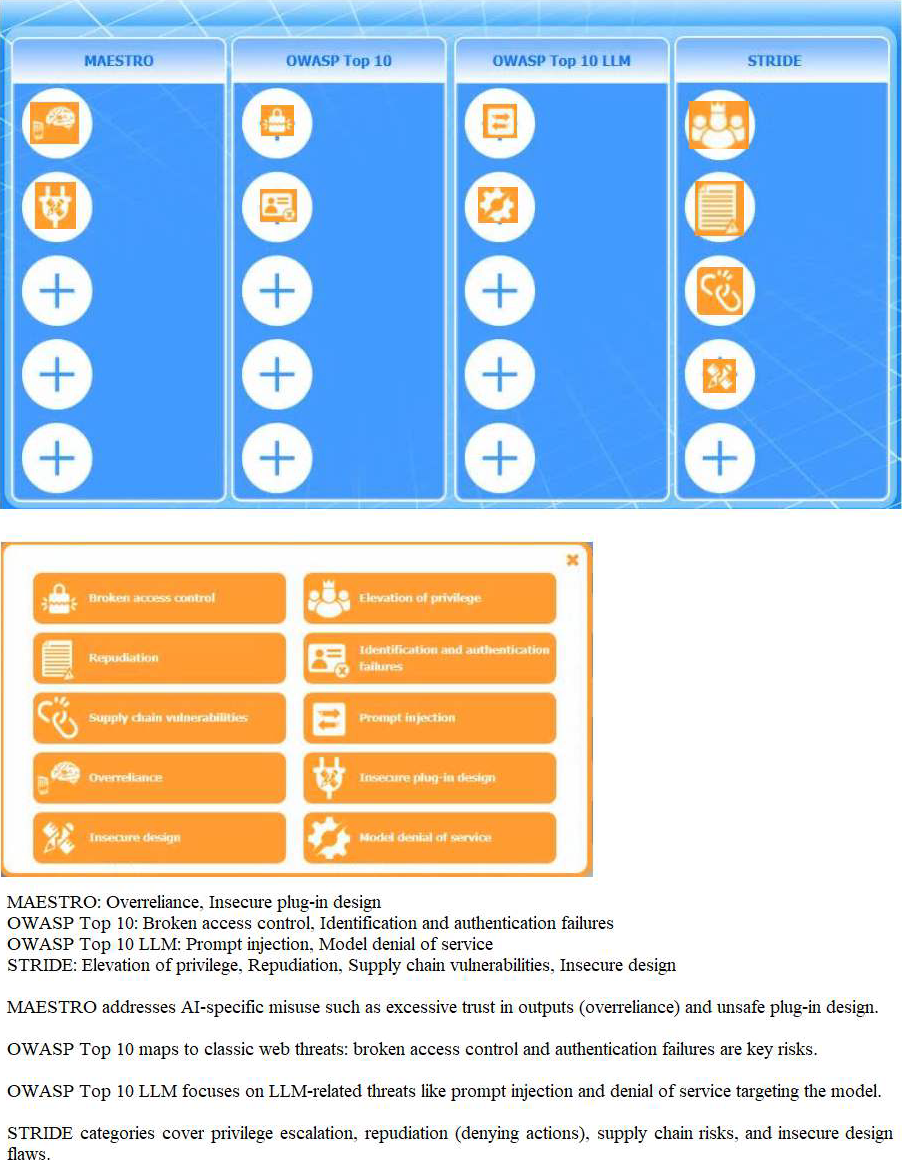
Instructions: Click the (+) to assign each threat category into its appropriate framework.
An architect is modeling an agentic system to meet security standards.
Answer : A
Basic Concept: This is a Performance-Based Question (PBQ) --- a simulation item requiring interactive drag-and-drop assignment of threat categories to appropriate frameworks in the actual exam. It tests knowledge of how different AI threat frameworks categorize and address specific threat types for agentic systems.
Key Concept --- Framework-to-Threat Mapping: MITRE ATLAS covers ML-specific adversarial tactics such as model evasion, data poisoning, model extraction, and prompt injection for agentic systems. OWASP LLM Top 10 addresses application-level LLM vulnerabilities such as insecure output handling, excessive agency, and supply chain risks. NIST AI RMF addresses governance-level risks across the AI lifecycle. STRIDE addresses architectural threats including spoofing, tampering, repudiation, information disclosure, DoS, and elevation of privilege.
Why This Matters: Agentic AI systems have a unique threat landscape combining traditional software vulnerabilities with AI-specific attacks. Correctly mapping threat categories to frameworks is essential for comprehensive threat modeling of systems that autonomously execute multi-step tasks with tool access and real-world consequences.
Question 4
Which of the following describe the practice of providing examples in a prompt? (Choose two.)
Answer : E, F
Basic Concept: Prompting techniques for LLMs include various approaches to guide model behavior. Providing examples within prompts is a powerful technique that leverages the model's in-context learning capability to guide response format and quality. CompTIA SecAI+ Study Guide covers prompting techniques under basic AI concepts.
Why E is Correct: One-shot prompting involves providing exactly one example within a prompt to demonstrate to the model the desired input-output format or response style. This single example guides the model's understanding of the task without requiring extensive fine-tuning. It is a well-established prompting technique that uses examples to inform model behavior.
Why F is Correct: Multi-shot prompting (also called few-shot prompting) involves providing multiple examples within a prompt to further clarify the desired output pattern. Multiple examples help the model identify consistent patterns and produce more accurate, consistent responses. Both one-shot and multi-shot are specifically defined by their use of examples in prompts.
Why A is Wrong: A user prompt is the input message submitted by a user to the AI system. It is the general term for any user input, not a specific technique that describes the practice of providing examples.
Why B is Wrong: A system prompt sets the model's behavior, persona, and constraints at the session level. While a system prompt could contain examples, the term specifically refers to the system-level instruction context, not the technique of example provision.
Why C is Wrong: A prompt template is a reusable structured format with placeholders for variable inputs. It standardizes prompt structure but is not defined by the practice of including examples.
Why D is Wrong: Quantization is a model compression technique that reduces model size by representing weights with lower precision numbers. It is a model optimization technique completely unrelated to prompting practices.
Question 5
A penetration tester is assessing the controls of a deployed AI system that is designed to search and return the contents of files.
The tester runs the following:
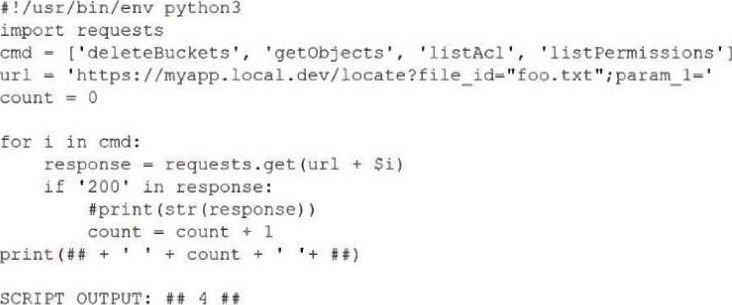
Which of the following is the best control to prevent abuse of the system?
Answer : D
Basic Concept: AI systems that access file systems or databases use service accounts to authenticate. Applying the principle of least privilege to these service accounts limits the damage that can result from prompt injection or other attacks that cause the AI to perform unauthorized file access. CompTIA SecAI+ Study Guide covers least privilege as a core AI security control.
Why D is Correct: Reducing the privilege scope of the service account implements the least privilege principle, ensuring the AI system can only access files it legitimately needs for its intended function. If an attacker uses prompt injection to abuse the file search capability, the service account's limited permissions prevent access to sensitive files outside the defined scope, containing the blast radius of any exploitation.
Why A is Wrong: Custom detection rules identify anomalous behavior after it occurs. They are detective controls, not preventive controls. They do not stop an attacker from successfully abusing the system; they only alert after abuse has occurred.
Why B is Wrong: VPC segmentation isolates the workload at the network level, limiting lateral movement. However, it does not restrict what files the AI's service account can access within its own environment, so file abuse attacks within the segment are still possible.
Why C is Wrong: LLM guardrails filter prompt inputs and outputs for policy violations. While useful, they can potentially be bypassed through sophisticated prompt injection. Reducing service account privileges provides a defense-in-depth layer that limits damage even if guardrails are bypassed.
Question 6
A healthcare organization plans to deploy a chatbot for appointment scheduling and patient records.
Which of the following is the first step a security administrator should take?
Answer : C
Basic Concept: Before implementing any security controls for an AI system, especially in a highly regulated sector such as healthcare, a risk assessment must first be conducted to understand the specific threats, vulnerabilities, regulatory obligations, and compliance requirements. CompTIA SecAI+ Study Guide emphasizes risk assessment as the foundational first step in any AI security program.
Why C is Correct: A risk assessment identifies what assets need protection, what threats exist, what regulations apply such as HIPAA for healthcare AI, and what the potential impact of various failure modes would be. In healthcare, this is especially critical given the sensitivity of patient records and strict regulatory requirements. The risk assessment results then inform and prioritize all subsequent security control implementations.
Why A is Wrong: Implementing prompt firewalls is a technical security control appropriate after risks have been identified and prioritized. Deploying controls before conducting a risk assessment may address the wrong threats or miss critical vulnerabilities.
Why B is Wrong: Role-based access management is a security control that should be designed based on identified roles and access requirements discovered during risk assessment. It is an implementation step, not the first step.
Why D is Wrong: Using a secure communication channel is a specific technical control for data in transit. While important, it addresses only one specific risk and should be implemented as part of a comprehensive security strategy informed by a prior risk assessment.
Question 7
An AI security administrator notices that the information referenced by the model is incorrectly formatted and missing values.
Which of the following job roles would most likely be responsible for correcting this error?
Answer : C
Basic Concept: In AI teams, different roles hold distinct responsibilities for specific aspects of the AI system. Data quality issues such as incorrect formatting and missing values fall within the domain of data engineering, which is responsible for designing, building, and maintaining the data pipelines and datasets that feed AI models. CompTIA SecAI+ Study Guide covers AI team role definitions under governance and basic AI concepts.
Why C is Correct: A Data Engineer is responsible for building and maintaining the data pipelines, transformation processes, and data quality controls that supply AI models with properly formatted, complete data. Addressing incorrectly formatted data and missing values is a core data engineering responsibility, as these professionals own the ETL (Extract, Transform, Load) processes, data validation rules, and data quality frameworks that ensure the model receives clean, usable input.
Why A is Wrong: A Platform Engineer designs and maintains the computing infrastructure and platforms that host AI systems. Their focus is the technical environment and deployment infrastructure, not the quality or formatting of the data consumed by models.
Why B is Wrong: An MLOps Engineer manages the deployment, monitoring, and operational lifecycle of AI models in production. While they may detect data quality issues through monitoring, resolving data formatting and missing value problems is the responsibility of data engineers who own the data pipelines.
Why D is Wrong: An AI Architect designs the overall AI system architecture, component interactions, and technical strategy. While they define data requirements, the hands-on work of correcting data formatting errors and filling missing values belongs to the data engineering function.