Page: 1
/ 14
Total 138 questions
Databricks Certified Professional Data Scientist Exam Questions
Question 1
What is the best way to evaluate the quality of the model found by an unsupervised algorithm like k-means clustering, given metrics for the cost of the clustering (how well it fits the data) and its stability (how similar the clusters are across multiple runs over the same data)?
Answer : A
Question 2
Under which circumstance do you need to implement N-fold cross-validation after creating a regression model?
Answer : B
Question 3
Which of the following are point estimation methods?
Answer : A, B, C
Question 4
A bio-scientist is working on the analysis of the cancer cells. To identify whether the cell is cancerous or not, there has been hundreds of tests are done with small variations to say yes to the problem. Given the test result for a sample of healthy and cancerous cells, which of the following technique you will use to determine whether a cell is healthy?
Answer : C
Question 5
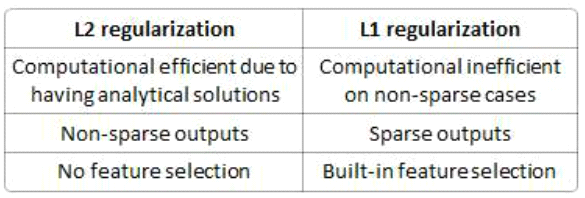
Select the correct option which applies to L2 regularization
Answer : A, B, C
The difference between their properties can be promptly summarized as follows:
Question 6
You are working in a data analytics company as a data scientist, you have been given a set of various types of Pizzas available across various premium food centers in a country. This data is given as numeric values like Calorie. Size, and Sale per day etc. You need to group all the pizzas with the similar properties, which of the following technique you would be using for that?
Answer : C
Question 7
You are working as a data science consultant for a gaming company. You have three member team and all other stake holders are from the company itself like project managers and project sponsored, data team etc. During the discussion project managed asked you that when can you tell me that the model you are using is robust enough, after which step you can consider answer for this question?
Answer : E