Page: 1
/ 14
Total 108 questions
Hortonworks Data Platform Certified Developer HDPCD Exam Questions
Question 1
For each input key-value pair, mappers can emit:
Answer : E
Mapper maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks that transform input records into intermediate records. The transformed intermediate records do not need to be of the same type as the input records. A given input pair may map to zero or many output pairs.
Question 2
Identify the MapReduce v2 (MRv2 / YARN) daemon responsible for launching application containers and monitoring application resource usage?
Answer : B
Question 3
How are keys and values presented and passed to the reducers during a standard sort and shuffle phase of MapReduce?
Answer : A
Reducer has 3 primary phases:
1. Shuffle
The Reducer copies the sorted output from each Mapper using HTTP across the network.
2. Sort
The framework merge sorts Reducer inputs by keys (since different Mappers may have output the same key).
The shuffle and sort phases occur simultaneously i.e. while outputs are being fetched they are merged.
SecondarySort
To achieve a secondary sort on the values returned by the value iterator, the application should extend the key with the secondary key and define a grouping comparator. The keys will be sorted using the entire key, but will be grouped using the grouping comparator to decide which keys and values are sent in the same call to reduce.
3. Reduce
In this phase the reduce(Object, Iterable, Context) method is called for each <key, (collection of values)> in the sorted inputs.
The output of the reduce task is typically written to a RecordWriter via TaskInputOutputContext.write(Object, Object).
The output of the Reducer is not re-sorted.
Question 4
Indentify which best defines a SequenceFile?
Answer : D
SequenceFile is a flat file consisting of binary key/value pairs.
There are 3 different SequenceFile formats:
Uncompressed key/value records.
Record compressed key/value records - only 'values' are compressed here.
Block compressed key/value records - both keys and values are collected in 'blocks' separately and compressed. The size of the 'block' is configurable.
Question 5
Which best describes how TextInputFormat processes input files and line breaks?
Answer : A
Question 6
Review the following data and Pig code:
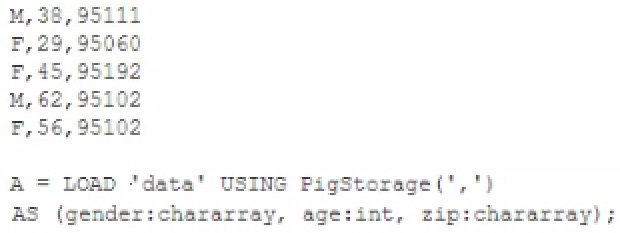
What command to define B would produce the output (M,62,95l02) when invoking the DUMP operator on B?
Answer : A
Question 7
Which HDFS command uploads a local file X into an existing HDFS directory Y?
Answer : C