Page: 1
/ 14
Total 50 questions
HP Advanced HPE Storage Integrator Solutions Written HPE7-J02 Exam Questions
Question 1
Your organization is implementing a new high-performance computing (HPC) cluster to support advanced scientific simul-ations. The cluster will consist of several hundred nodes that require rapid access to shared datasets. The storage is Vast/GL4F.
The application is very sensitive to latency and minimizing CPU overhead during data transfers is critical to achieving the desired performance levels.
Which access protocol should the organization implement to enhance NFS performance by reducing storage latency and increasing I/O operations?
Answer : B
Detailed Explanatio n:
Rationale for Correct Answe r:
For HPC and AI/ML workloads, NFS over RDMA (Remote Direct Memory Access) provides significantly lower latency and reduced CPU overhead compared to standard NFS over TCP. This allows direct memory-to-memory data transfers between storage and compute nodes, bypassing the kernel network stack. In VAST Data (underpinning GreenLake for File Storage), NFS over RDMA is explicitly supported to accelerate shared dataset access in HPC and AI environments.
Distractors:
A: Standard NFS introduces more latency due to kernel TCP/IP stack overhead.
C: RoCE (RDMA over Converged Ethernet) is a transport layer technology --- useful, but the protocol chosen for the file system must be NFS over RDMA, not just RoCE.
D: iSER (iSCSI Extensions for RDMA) enhances iSCSI block storage, not NFS file workloads.
Key Concept: NFS over RDMA for HPC/AI shared datasets.
Question 2
Review the diagram showing an Active Peer Persistence deployment across two arrays.
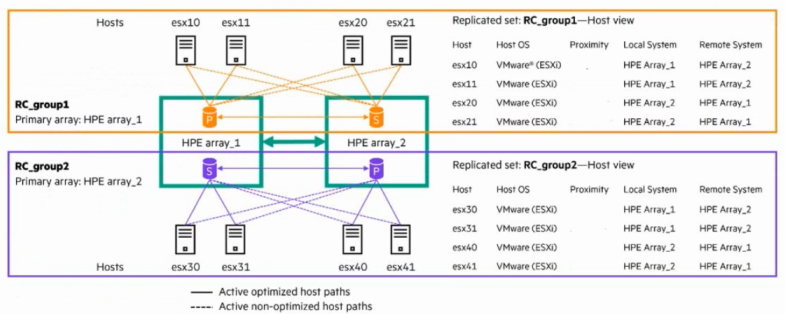
Question : Which Host Proximity Parameter should be configured for ESX31 to ensure localized access?
Answer : A
Question 3
You need to evaluate a customer's virtual server environment to size an HCI solution based on HPE SimpliVity according to usage metrics over time. The environment consists of Dell servers and storage running VMware virtualization.
Which action can you use to gather the usage metrics of this setup?
Answer : C
Detailed Explanatio n:
Rationale for Correct Answe r:
For competitive or 3rd-party (non-HPE) environments like Dell + VMware, HPE CloudPhysics is the correct tool. The Observer VM is deployed into vCenter to gather real-world workload metrics (CPU, memory, storage I/O). These analytics can then be used for SimpliVity HCI sizing.
Distractors:
A: NinjaOnline SimpliVity Sizer requires input metrics, but it cannot directly collect from 3rd-party environments.
B: InfoSight sizing applies to HPE arrays, not competitive storage.
D: InfoSight for SimpliVity only monitors existing HPE SimpliVity clusters.
Key Concept: CloudPhysics Observer gathers competitive workload metrics feeds into SimpliVity sizing.
Question 4
Your customer is a hospital that recently experienced an outage that impacted patient care. They are evaluating HPE SimpliVity.
Which statement about HPE SimpliVity RapidDR is correct?
Answer : D
Detailed Explanatio n:
Rationale for Correct Answe r:
HPE SimpliVity RapidDR simplifies and automates DR failover processes, but execution requires an authorized operator to trigger a pre-configured recovery plan. This balances automation with compliance and security requirements (important for healthcare). It does not guarantee zero RTO, but it does minimize RTO through automation.
Distractors:
A: RTO of 0 is not possible; RapidDR reduces but does not eliminate recovery time.
B: Domain admin credentials for re-IP are not required; automation handles reconfiguration.
C: Auto-commit/rollback require administrator validation; no ''silent'' automation is allowed for compliance.
Key Concept: RapidDR = automation of failover/failback but requires authorized trigger.
Question 5
Refer to the exhibit.
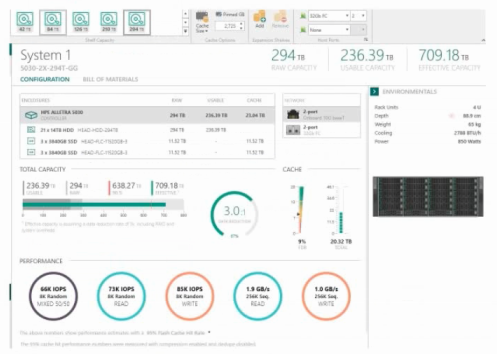
Which action plan would you suggest to correct the issue?
Answer : D
Detailed Explanatio n:
Rationale for Correct Answe r:
Frequent cache misses occur when the working dataset does not fit effectively in cache. Increasing the flash-to-disk ratio ensures a higher portion of hot data is served from flash media rather than backend disk, reducing cache miss penalties. This is the standard HPE recommendation for read-intensive workloads where cache is insufficient.
Distractors:
A: Adding shelves adds capacity, not cache-to-data efficiency.
B: Upgrading controllers increases CPU, but not necessarily cache efficiency.
C: Pinned cache is intended for metadata or specific workloads, not large-scale read caching.
Key Concept: Flash-to-disk ratio optimization reduces cache misses.
Question 6
You are migrating your customer's virtualization platform from an old third-party storage array to a newly installed HPE Alletra MP B10000 array. You are using HPE Zerto Move for the migration.
Which statement is correct when using HPE Zerto Move compared to the typical Failover feature?
Answer : C
Detailed Explanatio n:
Rationale for Correct Answe r:
When using Zerto Move, unlike a typical disaster recovery failover, the migration process allows the source VMs to be retained after cutover. This is useful when testing or validating the migration. In contrast, failover scenarios typically assume the source environment has failed or is decommissioned. Therefore, keeping source VMs is a differentiator for Move.
Distractors:
A: Checkpoints and RPO are controlled by Zerto replication but are not selectable per migration cutover in this way.
B: Source VMs are not deleted automatically; this is intentionally avoided to allow rollback.
D: While Zerto does provide low RPO/RTO (seconds to minutes), this applies mainly to DR failover, not migration cutovers.
Key Concept: Zerto Move vs Zerto Failover semantics.
Question 7
You are sizing an HPE Alletra 5030. Unless otherwise indicated by the HPE sizer or the customer's requirements, HPE best practices state that you should default to which minimum FDR calculation?
Answer : A
Detailed Explanatio n:
Rationale for Correct Answe r:
In Alletra 5000/6000 sizing, the Failure Domain Reserve (FDR) is used to account for rebuild overhead in case of drive failure. HPE best practices define that, unless otherwise directed by the sizing tool or customer requirements, the minimum FDR value should be set to 23% of the largest drive size. This ensures enough reserve capacity for fault tolerance and sustained performance during rebuilds.
Distractors:
B/C: Low-read latency is influenced by cache and workload profile, not by arbitrary FDR percentages.
D: Using the smallest drive is incorrect --- rebuild impact must be sized against the largest drive.
Key Concept: FDR sizing based on 23% of largest drive = HPE best practice.