Page: 1
/ 14
Total 408 questions
Microsoft Administering Microsoft Azure SQL Solutions DP-300 Exam Questions
Question 1
You have the following Transact-SQL query.
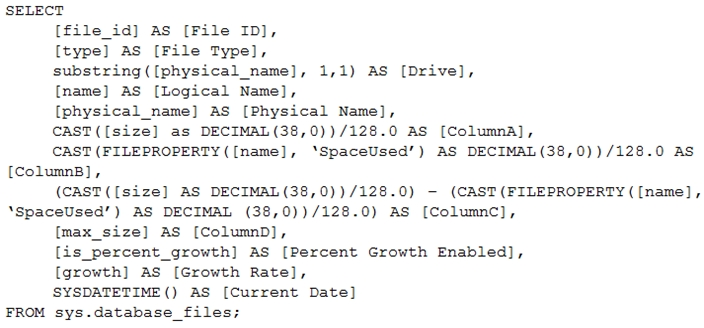
Which column returned by the query represents the free space in each file?
Answer : C
Example:
Free space for the file in the below query result set will be returned by the FreeSpaceMB column.
SELECT DB_NAME() AS DbName,
name AS FileName,
type_desc,
size/128.0 AS CurrentSizeMB,
size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS FreeSpaceMB
FROM sys.database_files
WHERE type IN (0,1);
https://www.sqlshack.com/how-to-determine-free-space-and-file-size-for-sql-server-databases/
Question 2
You have an Azure SQL managed instance that hosts multiple databases.
You need to configure alerts for each database based on the diagnostics telemetry of the database.
What should you use?
Answer : D
https://docs.microsoft.com/en-us/azure/azure-sql/database/metrics-diagnostic-telemetry-logging-streaming-export-configure?tabs=azure-portal#configure-the-streaming-export-of-diagnostic-telemetry
Question 3
You are designing an enterprise data warehouse in Azure Synapse Analytics that will contain a table named Customers. Customers will contain credit card information.
You need to recommend a solution to provide salespeople with the ability to view all the entries in Customers.
The solution must prevent all the salespeople from viewing or inferring the credit card information.
What should you include in the recommendation?
Answer : B
Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics support dynamic data masking. Dynamic data masking limits sensitive data exposure by masking it to non-privileged users.
The Credit card masking method exposes the last four digits of the designated fields and adds a constant string as a prefix in the form of a credit card.
Example:
XXXX-XXXX-XXXX-1234
Question 4
You have an Azure subscription that contains an Azure SQL managed instance named SQLMI1. You need to configure SQLMI1 to use the Business Critical service tier Which PowerShell cmdlet should you run?
Answer : D
Question 5
You have an Azure subscription. The subscription contains an instance of SQL Server on Azure Virtual Machines named SQL1 and an Azure Automation account named account1. You need to configure account1 to restart the SQL Server Agent service if the service stops. Which setting should you configure?
Answer : C
Question 6
You have an Azure SQL database named DB1.
You need to ensure that DB1 will support automatic failover without data loss if a datacenter fails. The solution must minimize costs.
Which deployment option and pricing tier should you configure?
Answer : C
By default, the cluster of nodes for the premium availability model is created in the same datacenter. With the introduction of Azure Availability Zones, SQL Database can place different replicas of the Business Critical database to different availability zones in the same region. To eliminate a single point of failure, the control ring is also duplicated across multiple zones as three gateway rings (GW). The routing to a specific gateway ring is controlled by Azure Traffic Manager (ATM). Because the zone redundant configuration in the Premium or Business Critical service tiers does not create additional database redundancy, you can enable it at no extra cost. By selecting a zone redundant configuration, you can make your Premium or Business Critical databases resilient to a much larger set of failures, including catastrophic datacenter outages, without any changes to the application logic. You can also convert any existing Premium or Business Critical databases or pools to the zone redundant configuration.
Incorrect Answers:
https://docs.microsoft.com/en-us/azure/azure-sql/database/high-availability-sla
Question 7
You have two on-premises Microsoft SQL Server 2019 instances named SQL1 and SQL2.
You need to migrate the databases hosted on SQL 1 to Azure. The solution must meet the following requirements:
The service that hosts the migrated databases must be able to communicate with SQL2 by using linked server connections.
Administrative effort must be minimized.
What should you use to host the databases?
Answer : D