Page: 1
/ 14
Total 129 questions
Microsoft Implementing Data Engineering Solutions Using Microsoft Fabric DP-700 Exam Questions
Question 1
You have a Fabric workspace that contains an eventstream named EventStream1. EventStream1 outputs events to a table in a lakehouse.
You need to remove files that are older than seven days and are no longer in use.
Which command should you run?
Answer : A
VACUUM is used to clean up storage by removing files no longer in use by a Delta table. It removes old and unreferenced files from Delta tables. For example, to remove files older than 7 days:
VACUUM delta.`/path_to_table` RETAIN 7 HOURS;
Question 2
You are building a Fabric notebook named MasterNotebookl in a workspace. MasterNotebookl contains the following code.

You need to ensure that the notebooks are executed in the following sequence:
1. Notebook_03
2. Notebook.Ol
3. Notebook_02
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
Answer : C, E
Question 3
You have a Fabric workspace that contains a lakehouse named Lakehouse1. Lakehouse1 contains a table named Table 1. You need to ensure that a user named User 1 can view only specific rows in Table1. What should you do first?
Answer : A
Question 4
You have a Fabric workspace named Workspace1 that contains a warehouse named DW1 and a data pipeline named Pipeline1.
You plan to add a user named User3 to Workspace1.
You need to ensure that User3 can perform the following actions:
View all the items in Workspace1.
Update the tables in DW1.
The solution must follow the principle of least privilege.
You already assigned the appropriate object-level permissions to DW1.
Which workspace role should you assign to User3?
Answer : D
To ensure User3 can view all items in Workspace1 and update the tables in DW1, the most appropriate workspace role to assign is the Contributor role. This role allows User3 to:
View all items in Workspace1: The Contributor role provides the ability to view all objects within the workspace, such as data pipelines, warehouses, and other resources.
Update the tables in DW1: The Contributor role allows User3 to modify or update resources within the workspace, including the tables in DW1, assuming that appropriate object-level permissions are set for the warehouse.
This role adheres to the principle of least privilege, as it provides the necessary permissions without granting broader administrative rights.
Question 5
You have a Fabric workspace that contains a data pipeline named Pipeline! as shown in the exhibit.
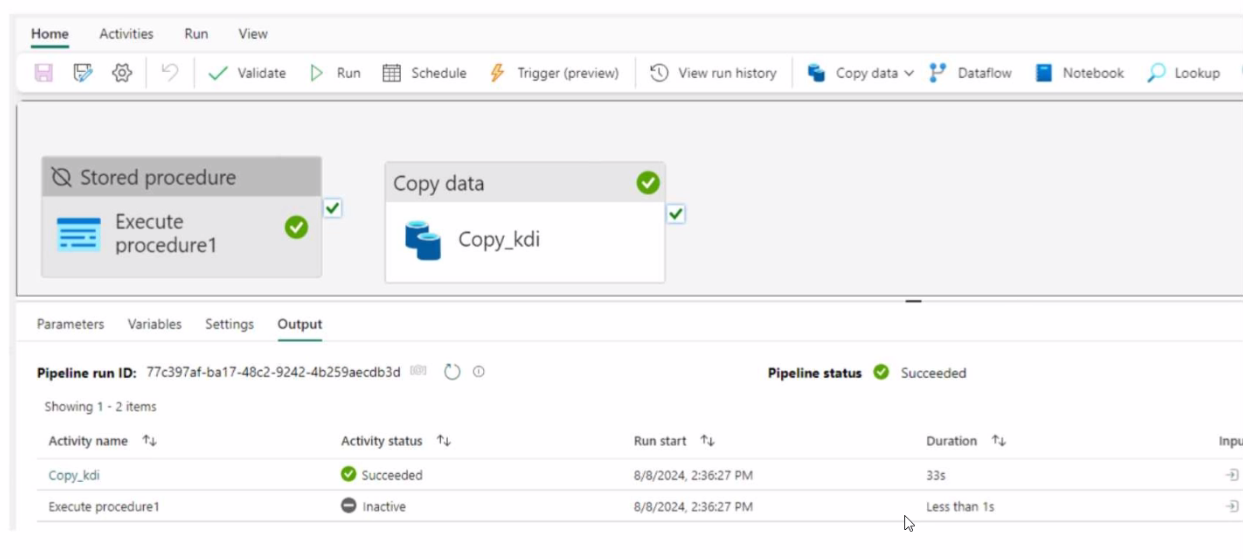
Answer : B
Question 6
You need to ensure that WorkspaceA can be configured for source control. Which two actions should you perform?
Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
Answer : A, B
Question 7
You need to recommend a solution to resolve the MAR1 connectivity issues. The solution must minimize development effort. What should you recommend?
Answer : B