Page: 1
/ 14
Total 61 questions
Microsoft Developing AI-Enabled Database Solutions DP-800 Exam Questions
Question 1
You have an Azure SQL database that supports a customer-facing API. The API calls a stored procedure named dbo.GetCustomerOrders thousands of times per hour.
After a deployment that updated indexes and statistics, users report that the API endpoint backed by dbo.Getcustomerorders is slower. In Query Store, the same query now has two persisted execution plans. During the last hour, the newer plan had a significantly higher average duration and CPU time than the older plan.
You need to restore the previous performance quickly, without changing the API code.
Which Transact-SQL command should you run?
Answer : C
The scenario says Query Store already shows two persisted execution plans for the same query, and the older plan performed much better than the newer one during the last hour. Microsoft documents that sp_query_store_force_plan is used to force a particular plan for a particular query in Query Store. That makes it the fastest way to restore the previously good plan without changing application code, which is exactly what the question requires.
Why the other options are not the best fit:
sp_query_store_set_hints is for adding or updating Query Store hints to influence compilation behavior, but when you already know the exact older good plan, Microsoft points to plan forcing as the direct remedy.
DBCC FREEPROCCACHE clears cached plans broadly and is disruptive; it does not guarantee a return to the known good plan.
ALTER DATABASE is too general and does not directly restore the prior execution plan.
So the right Transact-SQL command is:
EXEC sp_query_store_force_plan
using the relevant @query_id and @plan_id from Query Store for the older, better-performing plan. Microsoft also notes that when a plan is forced, SQL Server tries to use that plan whenever it encounters the query again.
Question 2
You have a Microsoft SQL Server 2025 instance that has a managed identity enabled.
You have a database that contains a table named dbo.ManualChunks. dbo.ManualChunks contains product manuals.
A retrieval query already returns the top five matching chunks as nvarchar(max) text.
You need to call an Azure OpenAI REST endpoint for chat completions. The solution must provide the highest level of security.
You write the following Transact-SG1 code.
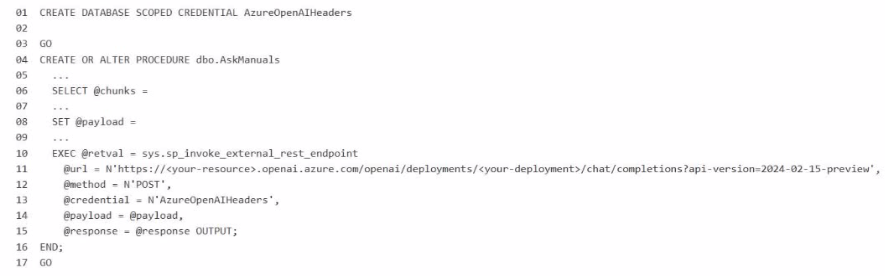
What should you insert at line 02?
A)

B)

C)

D)

E)

Answer : B
The correct answer is Option B because the requirement is to call an Azure OpenAI REST endpoint from SQL Server 2025 while providing the highest level of security, and the instance already has a managed identity enabled. For Microsoft's SQL AI features, the preferred secure pattern is to use a database scoped credential with IDENTITY = 'Managed Identity' instead of storing an API key. Microsoft documents that SQL Server 2025 supports managed identity for external AI endpoints, and for Azure OpenAI the credential secret uses the Cognitive Services resource identifier: {'resourceid':'https://cognitiveservices.azure.com'}.
So line 02 should be:
WITH IDENTITY = 'Managed Identity', SECRET = '{'resourceid':'https://cognitiveservices.azure.com'}';
Why the other options are incorrect:
A and D use HTTP header or query-string credentials with an API key, which is less secure than managed identity because a secret key must be stored and rotated manually. Microsoft recommends managed identity where supported to avoid embedded secrets.
C mixes Managed Identity with an api-key secret, which is not the correct pattern for Azure OpenAI managed-identity authentication.
E uses an invalid identity value for this scenario. The accepted credential identities for external REST endpoint calls include HTTPEndpointHeaders, HTTPEndpointQueryString, Managed Identity, and Shared Access Signature.
Because the endpoint is Azure OpenAI and the question explicitly asks for the highest security, managed identity with the Cognitive Services resource ID is the Microsoft-aligned answer.
Question 3
You need to recommend a solution to lesolve the slow dashboard query issue. What should you recommend?
Answer : B
The best recommendation is B because the slow query filters on FleetId and returns LastUpdatedUtc, EngineStatus, and BatteryHealth. A nonclustered index with FleetId as the key column allows the optimizer to perform an index seek instead of a clustered index scan, and including the other selected columns makes the index covering, which reduces extra lookups and I/O. Microsoft's SQL Server indexing guidance states that a nonclustered index with included columns can significantly improve performance when all query columns are available in the index, because the optimizer can satisfy the query directly from the index.
The query is:
SELECT VehicleId, LastUpdatedUtc, EngineStatus, BatteryHealth FROM dbo.VehicleHealthSummary WHERE FleetId = @FleetId ORDER BY LastUpdatedUtc DESC;
Among the given choices, FleetId is the most important search argument because it appears in the WHERE predicate. Microsoft's index design guidance recommends putting columns used for searching in the key and using nonkey included columns to cover the rest of the query efficiently.
Why the other options are weaker:
A is not appropriate because changing the clustered index to LastUpdatedUtc would not target the main filter predicate on FleetId, and a table can have only one clustered index.
C makes LastUpdatedUtc the key, which is poor for a query whose primary filter is FleetId.
D is not the right answer here because the query requirement does not specify only recent rows, and filtered indexes are meant for a well-defined subset; this option also uses a time-based expression that is not aligned to the stated query pattern.
Strictly speaking, the most optimal design for both filtering and ordering would usually be a composite key like (FleetId, LastUpdatedUtc), but since that is not one of the available options, B is the correct exam answer.
Question 4
You have an Azure SQL database.
You need to create a scalar user-defined function (UDF) that returns the number of whole years between an input parameter named 0orderDate and the current date/time as a single positive integer. The function must be created in Azure SQL Database. You write the following code.

What should you insert at line 05?
Answer : D
The correct answer is D because the scalar UDF must return the number of whole years from the input @OrderDate to the current date/time as a single positive integer. The correct DATEDIFF order is:
DATEDIFF(year, @OrderDate, GETDATE())
Microsoft documents that DATEDIFF(datepart, startdate, enddate) returns the count of specified datepart boundaries crossed between the start and end values. Since @OrderDate is the earlier date and GETDATE() is the later date, this ordering returns a positive result for past order dates.
The other choices are incorrect:
A reverses the arguments and would return a negative value for a past order date.
B is missing RETURN, and converting month difference to years by dividing by 12 is not the direct whole-year expression the question asks for.
C subtracts year parts only, which can be off around anniversary boundaries because it ignores whether the full year has actually elapsed.
So the correct insertion at line 05 is:
RETURN DATEDIFF(year, @OrderDate, GETDATE());
Question 5
You have a database named DB1. The schema is stored in a Git repository as an SDK-style SQL database project.
You have a GitHub Actions workflow that already runs dotnet build and produces a database artifact.
You need to add a deployment step that publishes the dacpac file to an Azure SQL database by using the secrets stored in GitHub repository secrets
What should you include in the workflow?
A)
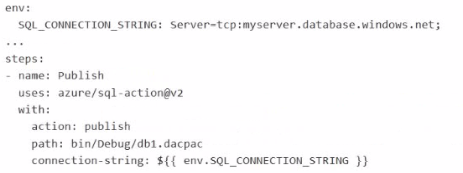
B)
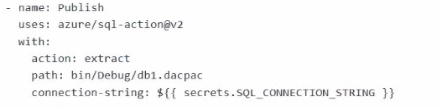
C)

D)

Answer : C
The correct workflow step is Option C because it uses the Azure SQL GitHub Action to publish a .dacpac file and reads the connection string from GitHub repository secrets, which is exactly what the requirement asks for. Microsoft's Azure SQL GitHub Actions guidance shows using azure/sql-action@v2 with a connection string stored in secrets and a DACPAC path for deployment.
The key parts that make C correct are:
uses: azure/sql-action@v2
action: publish
path: bin/Debug/db1.dacpac
connection-string: ${{ secrets.SQL_CONNECTION_STRING }}
That matches the documented publish pattern for deploying a DACPAC to Azure SQL Database from GitHub Actions. Microsoft and the Azure SQL action documentation both describe Publish as the deployment action for applying a DACPAC to a target database, while Extract is used to create a DACPAC from an existing database, not deploy one.
Why the other options are incorrect:
A uses an environment variable defined inline with a visible connection string rather than using GitHub repository secrets, which does not meet the requirement.
B uses action: extract, which would create a DACPAC from a database instead of publishing the existing DACPAC artifact.
D passes a target connection string to dotnet build, but the question says the workflow already runs dotnet build and produces a database artifact. The missing step is the deployment/publish step, not another build step. Microsoft's SQL project automation guidance separates build the DACPAC from publish the DACPAC.
Question 6
You have an Azure SQL database that contains the following SQL graph tables:
* A NODE table named dbo.Person
* An EDGE table named dbo.Knows
Each row in dbo.Person contains the following columns:
* Personid (int)
* DisplayName (nvarchar(100))
You need to use a HATCH operator and exactly two directed Knows relationships to return the Personid and DisplayName of people that are reachable from the person identified by an input parameter named @startPersonid.
Which Transact-SQL query should you use?
A)

B)

C)

D)

Answer : D
The correct query is Option D because it starts from the input person and uses exactly two directed Knows edges in a single MATCH pattern:
MATCH(p1-(k1)->p2-(k2)->p3)
Microsoft documents that SQL Graph uses the MATCH predicate in the WHERE clause to express graph traversal patterns over node and edge tables, and directed relationships are written with arrow syntax such as node1-(edge)->node2.
Why D is correct:
It anchors the starting node with p1.PersonId = @StartPersonId.
It traverses two directed hops: p1 -> p2 -> p3.
It returns p3.PersonId, p3.DisplayName, which are the people reachable in exactly two Knows relationships.
Why the others are wrong:
A filters on DisplayName = DisplayName, which is unrelated to the required input parameter and does not correctly anchor the start node.
B reverses the traversal direction in the pattern.
C uses two separate MATCH predicates instead of the required single two-hop directed pattern. The proper graph pattern syntax supports chaining the hops directly in one MATCH expression.
Question 7
You have a GitHub Actions workflow that builds and deploys an Azure SQL database. The schema is stored in a GitHub repository as an SDK-style SQL database project.
Following a code review, you discover that you need to generate a report that shows whether the production schema has diverged from the model in source control.
Which action should you add to the pipeline?
Answer : A
Microsoft documents that DriftReport creates an XML report showing changes that have been made to the registered database since it was last registered. That is the action intended to detect whether the production schema has diverged from the expected model baseline in your deployment workflow.
This is different from DeployReport, which shows the changes that would be made by a publish action. In other words:
DriftReport answers: Has the deployed database drifted from the registered state/model?
DeployReport answers: What changes would be applied if I published now?
The other options are not the right fit:
Extract creates a DACPAC from an existing database, not a drift analysis report.
Script generates a deployment script, not a schema-drift report.
So to generate a report that shows whether production has diverged from the model in source control, add:
SqlPackage.exe /Action:DriftReport