Page: 1
/ 14
Total 152 questions
Salesforce Certified MuleSoft Platform Architect (Mule-Arch-201) Exam Questions
Question 1
When using CloudHub with the Shared Load Balancer, what is managed EXCLUSIVELY by the API implementation (the Mule application) and NOT by Anypoint Platform?
Answer : C
Correct Answe r: The SSL certificates used by the API implementation to expose HTTPS endpoints
*****************************************
>> The assignment of each HTTP request to a particular CloudHub worker is taken care by Anypoint Platform itself. We need not manage it explicitly in the API implementation and in fact we CANNOT manage it in the API implementation.
>> The logging configuration that enables log entries to be visible in Runtime Manager is ALWAYS managed in the API implementation and NOT just for SLB. So this is not something we do EXCLUSIVELY when using SLB.
>> We DO NOT manage the number of DNS entries allocated to the API implementation inside the code. Anypoint Platform takes care of this.
It is the SSL certificates used by the API implementation to expose HTTPS endpoints that is to be managed EXCLUSIVELY by the API implementation. Anypoint Platform does NOT do this when using SLBs.
Question 2
An API is protected with a Client ID Enforcement policy and uses the default configuration. Access is requested for the client application to the API, and an approved
contract now exists between the client application and the API
How can a consumer of this API avoid a 401 error "Unauthorized or invalid client application credentials"?
Answer : C
When using the Client ID Enforcement policy with default settings, MuleSoft expects the client_id and client_secret to be provided in the URI parameters of each request. This policy is typically used to control and monitor access by validating that each request has valid credentials. Here's how to avoid a 401 Unauthorized error:
URI Parameters Requirement:
The default configuration for the Client ID Enforcement policy requires the client_id and client_secret to be included in each request's URI parameters. This is a straightforward way to authenticate API requests without additional configurations.
Why Option C is Correct:
Providing client_id and client_secret in the URI parameters meets the policy's requirements for each request, ensuring authorized access and avoiding the 401 error.
of Incorrect Options:
Option A (sending a token in the header) would be applicable for token-based authentication (like OAuth 2.0), not Client ID Enforcement.
Option B (request body) and Option D (header) are not valid locations for client_id and client_secret under the default configuration of Client ID Enforcement, which expects them in the URI.
Reference For more details, consult MuleSoft's documentation on Client ID Enforcement policies and expected request configurations
Question 3
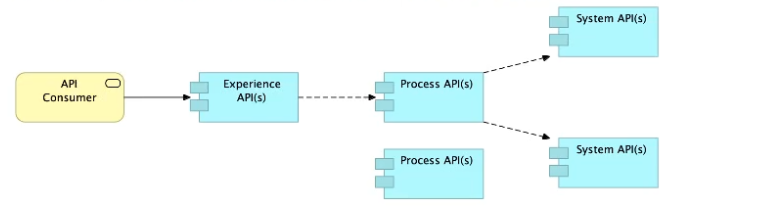
Refer to the exhibit.
What is the best way to decompose one end-to-end business process into a collaboration of Experience, Process, and System APIs?
A) Handle customizations for the end-user application at the Process API level rather than the Experience API level
B) Allow System APIs to return data that is NOT currently required by the identified Process or Experience APIs
C) Always use a tiered approach by creating exactly one API for each of the 3 layers (Experience, Process and System APIs)
D) Use a Process API to orchestrate calls to multiple System APIs, but NOT to other Process APIs
Answer : B
Correct Answe r: Allow System APIs to return data that is NOT currently required by the identified Process or Experience APIs.
*****************************************
>> All customizations for the end-user application should be handled in 'Experience API' only. Not in Process API
>> We should use tiered approach but NOT always by creating exactly one API for each of the 3 layers. Experience APIs might be one but Process APIs and System APIs are often more than one. System APIs for sure will be more than one all the time as they are the smallest modular APIs built in front of end systems.
>> Process APIs can call System APIs as well as other Process APIs. There is no such anti-design pattern in API-Led connectivity saying Process APIs should not call other Process APIs.
So, the right answer in the given set of options that makes sense as per API-Led connectivity principles is to allow System APIs to return data that is NOT currently required by the identified Process or Experience APIs. This way, some future Process APIs can make use of that data from System APIs and we need NOT touch the System layer APIs again and again.
Question 4
Which out-of-the-box key performance indicator measures the success of a typical Center for Enablement and is immediately available in responses from Anypoint Platform APIs?
Answer : D
Center for Enablement (C4E) KPIs:
A Center for Enablement (C4E) in MuleSoft focuses on enabling self-service and reuse by providing APIs that can be consumed across the organization. A key metric of success is how many consumers are utilizing the published APIs.
The number of consumers who have requested and received access to an API indicates the level of adoption and reuse, which aligns with the goals of a C4E.
Evaluating the Options:
Option A: This metric could indicate deployment automation, but it is not a direct measure of C4E's success in enabling API reuse and consumption.
Option B: Bandwidth usage per API implementation provides insight into API traffic but does not measure C4E enablement or consumer engagement.
Option C: The number of developers downloading an API specification can be an indicator of interest but does not confirm actual usage or enablement.
Option D (Correct Answer): The number of consumers who have requested and received access to an API in production is a key metric indicating API adoption and reuse, which aligns with C4E's goals.
Conclusion:
Option D is the correct answer as it provides a direct measure of consumer engagement and adoption, indicating the success of the C4E in promoting API usage across the organization.
Refer to MuleSoft's documentation on C4E KPIs and API usage metrics for additional insights.
Question 5
An API implementation is being designed that must invoke an Order API, which is known to repeatedly experience downtime.
For this reason, a fallback API is to be called when the Order API is unavailable.
What approach to designing the invocation of the fallback API provides the best resilience?
Answer : A
Correct Answe r: Search Anypoint exchange for a suitable existing fallback API, and then implement invocations to this fallback API in addition to the order API
*****************************************
>> It is not ideal and good approach, until unless there is a pre-approved agreement with the API clients that they will receive a HTTP 3xx temporary redirect status code and they have to implement fallback logic their side to call another API.
>> Creating separate entry of same Order API in API manager would just create an another instance of it on top of same API implementation. So, it does NO GOOD by using clone od same API as a fallback API. Fallback API should be ideally a different API implementation that is not same as primary one.
>> There is NO option currently provided by Anypoint HTTP Connector that allows us to invoke a fallback API when we receive certain HTTP status codes in response.
The only statement TRUE in the given options is to Search Anypoint exchange for a suitable existing fallback API, and then implement invocations to this fallback API in addition to the order API.
Question 6
Which component monitors APIs and endpoints at scheduled intervals, receives reports about whether tests pass or fail, and displays statistics about API and endpoint
performance?
Answer : C
Understanding API Functional Monitoring:
API Functional Monitoring is a feature within MuleSoft's Anypoint Platform that enables users to monitor the health and performance of APIs and endpoints by running functional tests at scheduled intervals.
It checks whether APIs are functioning as expected by running test calls and then evaluating if the response meets the desired conditions. This is particularly useful for testing endpoint availability, checking for specific data in responses, and measuring API performance over time.
Component Features:
Scheduled Intervals: Functional monitoring allows configuring tests to run at regular intervals, such as every minute, hour, or day, depending on the monitoring requirements.
Reports on Test Pass/Fail Status: After each test run, API Functional Monitoring reports whether the API passed or failed the test conditions.
Performance Statistics: It displays metrics like average response time, success rate, and error rates, giving insights into API health and performance.
Evaluating the Options:
Option A (API Analytics): API Analytics provides insights on API usage and metrics but does not involve scheduled tests for pass/fail status or endpoint health checks.
Option B (Anypoint Monitoring Dashboards): These dashboards display API metrics but do not actively test API endpoints or provide pass/fail reporting on a scheduled basis.
Option C (Correct Answer): API Functional Monitoring fits the description, as it is designed to monitor API and endpoint health with scheduled test runs and display statistics about performance.
Option D (Anypoint Runtime Manager Alerts): Runtime Manager alerts notify users of issues with application status but do not actively test endpoints at scheduled intervals.
Conclusion:
Option C (API Functional Monitoring) is the correct answer because it provides the necessary tools to test API functionality, monitor endpoint health, and display performance statistics in real-time.
Refer to MuleSoft documentation on API Functional Monitoring for further guidance on setting up and configuring these tests in Anypoint Platform.
Question 7
An organization is implementing a Quote of the Day API that caches today's quote.
What scenario can use the GoudHub Object Store via the Object Store connector to persist the cache's state?
Answer : D
Correct Answe r: When there is one CloudHub deployment of the API implementation to three CloudHub workers that must share the cache state.
*****************************************
Key details in the scenario:
>> Use the CloudHub Object Store via the Object Store connector
Considering above details:
>> CloudHub Object Stores have one-to-one relationship with CloudHub Mule Applications.
>> We CANNOT use an application's CloudHub Object Store to be shared among multiple Mule applications running in different Regions or Business Groups or Customer-hosted Mule Runtimes by using Object Store connector.
>> If it is really necessary and very badly needed, then Anypoint Platform supports a way by allowing access to CloudHub Object Store of another application using Object Store REST API. But NOT using Object Store connector.
So, the only scenario where we can use the CloudHub Object Store via the Object Store connector to persist the cache's state is when there is one CloudHub deployment of the API implementation to multiple CloudHub workers that must share the cache state.