Page: 1
/ 14
Total 60 questions
NetApp certified support engineer - ONTAP specialist NS0-593 Exam Questions
Question 1
You have a 4-node NetApp ONTAP 9.8 cluster with an AFF A400 HA pair and a FAS8300 HA pair with 16 TB NL-SAS drives. You are asked to automatically tier 150 TB of Snapshot copy data from the AFF A400 aggregates to the FAS8300.
In this scenario, which ONTAP license must be added to the cluster to accomplish this task?
Answer : D
FabricPool is an ONTAP feature that enables tiering of cold data from SSD aggregates to low-cost object storage, either on-premises or in the cloud1.FabricPool requires a license to be installed on the cluster, and the license type depends on the cloud tier being used2.In this scenario, the cloud tier is another ONTAP cluster (FAS8300), which is not supported by the new Cloud Tiering license that is used for most FabricPool configurations3.Therefore, the old FabricPool license that is retained for dark sites or MetroCluster systems using FabricPool Mirror must be used3.The FabricPool license defines the amount of capacity that can be tiered to the cloud tier, and it can be increased by add-on orders4.Reference:
1: FabricPool overview5
2: FabricPool requirements6
3: Install a FabricPool license2
4: ONTAP FabricPool (FP) Licensing Overview1
Question 2
Recently, a CIFS SVM was deployed and is working. The customer wants to use the Dynamic DNS (DDNS) capability available in NetApp ONTAP to easily advertise both data UFs to their clients. Currently. DNS is only responding with one data LIF. DDNS is enabled on the domain controllers.
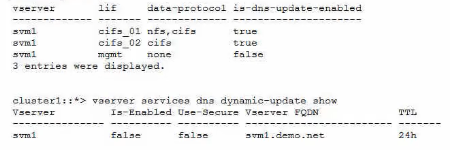
Referring to the exhibit, which two actions should be performed to enable DDNS updates to work? (Choose two.)
Answer : B, D
To enable DDNS updates to work, two actions should be performed:
Remove the NFS protocol from the cifs_01 data LIF.This is because DDNS updates are only supported for LIFs that have only one data protocol enabled1. The cifs_01 LIF has both NFS and CIFS protocols enabled, which prevents it from registering its DNS record dynamically. By removing the NFS protocol from the cifs_01 LIF, it will become eligible for DDNS updates.
Enable the -is-enabled parameter for the SVM DDNS services.This is because the -is-enabled parameter controls whether the SVM sends DDNS updates to the DNS servers2. The exhibit shows that the -is-enabled parameter is set to false for the svm1 SVM, which means that it does not send any DDNS updates. By enabling the -is-enabled parameter, the SVM will start sending DDNS updates for its eligible LIFs.Reference:
1: Configure dynamic DNS services3
2: Manage DNS/DDNS services with System Manager4
Question 3
You recently discovered the error message shown below in your ONTAP logs.
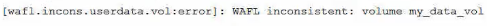
What should be your first action to correct this Issue?
Answer : B
= The error message indicates that the volume my_data_vol is WAFL inconsistent, which means that there is a discrepancy between the data blocks and the metadata in the file system. This can be caused by various factors, such as hardware failures, software bugs, power outages, or network disruptions.The first action to correct this issue is to determine the root cause behind the inconsistency before attempting any recovery procedure, as recommended by the NetApp documentation1. This is because some recovery procedures, such as wafliron or storage takeover, may not work or may cause further damage if the underlying cause is not resolved. For example, if the inconsistency is due to a faulty disk or shelf, running wafliron may not fix the problem and may even corrupt more data.Therefore, it is important to identify and isolate the cause of the inconsistency before taking any further steps.Reference=1Volume Showing WAFL Inconsistent - NetApp Knowledge Base
Question 4
Refer to the exhibit.
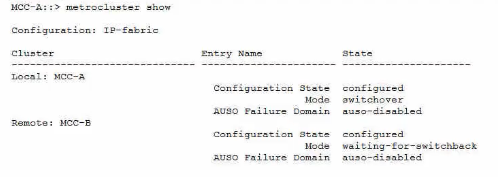
Referring to the exhibit, what do you need to do to return the MetroCluster to a normal state?
Answer : B
The question refers to a MetroCluster configuration, which is a disaster recovery solution that uses two physically separated, mirrored clusters1.
The exhibit shows a MetroCluster switchover scenario, where Site A has experienced a disaster and Site B has taken over the tasks of Site A2.
To return the MetroCluster to a normal state, you need to perform a MetroCluster switchback operation, which reverses the switchover and activates the original sync-source storage virtual machines (SVMs) on Site A3.
To perform a MetroCluster switchback, you need to enter themetrocluster switchbackcommand on the cluster that was the source of the switchover, which is Site A in this case3.
The other options are not correct, because:
A)Entering themetrocluster switchbackcommand on Site B will not work, as Site B is the destination of the switchover, not the source3.
C)Entering thestorage failover givebackcommand on Site B will not work, as this command is used for local HA failover within a cluster, not for MetroCluster switchover between clusters4.
D)Entering thestorage failover givebackcommand on Site A will not work, as this command is used for local HA failover within a cluster, not for MetroCluster switchover between clusters4.Reference:
Understanding MetroCluster data protection and disaster recovery - NetApp
Perform IP MetroCluster switchover and switchback - NetApp
Performing a switchback - NetApp
High-availability configuration - NetApp
Question 5
You have a customer who is concerned with high CPU and disk utilization on their SnapMirror destination system. They are worried about high CPU and disk usage without any user operations.
In this situation, what should you tell the customer?
Answer : B
SnapMirror is a data replication technology that allows efficient and flexible data protection and disaster recovery for NetApp ONTAP storage systems1
SnapMirror transfers data between source and destination volumes using a network connection.SnapMirror can use storage efficiency features such as compression and deduplication to reduce the amount of data transferred and stored1
SnapMirror transfers are scheduled and controlled by policies that define the frequency, retention, and priority of the transfers.SnapMirror policies can also specify the network bandwidth limit for the transfers2
SnapMirror transfers are considered background tasks that run in the absence of user workload.SnapMirror transfers can consume CPU and disk resources on both source and destination systems, depending on the amount and type of data being replicated3
SnapMirror transfers can throttle up or down depending on the availability of system resources and network bandwidth. SnapMirror transfers will throttle up when there is no user workload, and throttle down when there is user workload.This is to ensure that SnapMirror transfers do not impact the performance of user operations3
Therefore, if a customer is concerned with high CPU and disk utilization on their SnapMirror destination system, the best answer is to explain that background tasks such as SnapMirror throttle up in the absence of user workload.This is normal and expected behavior, and it does not indicate a problem with the system3
1: ONTAP 9 Data Protection - SnapMirror - The Open Group2: ONTAP 9 Data Protection - SnapMirror Policies - The Open Group3: SnapMirror storage efficiency configurations and behavior - Resolution Guide - NetApp Knowledge Base
Question 6
You want to assign storage access to an NVMe protocol host.
Which three objects must be configured to accomplish this task? (Choose three.)
Answer : A, C, D
To assign storage access to an NVMe protocol host, you need to configure the following objects:
TheNVMe subsystem, which is a logical entity that represents a group of NVMe namespaces that can be accessed by one or more hosts1.
AnNVMe LIF, which is a logical interface that provides network connectivity for the NVMe subsystem2.
TheNVMe namespace, which is a logical volume that is exposed to the host as an NVMe device1.
You do not need to configure the NVMe broadcast domain or the NVMe LUN, as these are not relevant for NVMe protocol host access.Reference=1:Configuring NVMe-oF - Hitachi Vantara Knowledge2:Basic VMware NVMe Architecture and Components
Question 7
You are attempting to connect a NetApp ONTAP cluster to a very complex network that requires LIFs to fail over across subnets.
How would you accomplish this task?
Answer : C
A LIF (Logical Interface) is a logical entity that represents a network connection point on a node1.
A VIP LIF (Virtual IP LIF) is a LIF that can fail over across subnets within an IPspace2.
BGP (Border Gateway Protocol) is a routing protocol that enables VIP LIFs to advertise their IP addresses to external routers and to update the routing tables when a failover occurs3.
To connect a NetApp ONTAP cluster to a complex network that requires LIFs to fail over across subnets, you need to configure VIP LIFs using BGP on the cluster and on the external routers3.
This way, you can ensure that the network traffic is routed to the optimal node and port for each VIP LIF, and that the network connectivity is maintained in the event of a node or port failure3.Reference:
1: Logical Interfaces, ONTAP 9 Documentation Center
2: VIP LIFs, ONTAP 9 Documentation Center
3: Configuring BGP on a cluster, ONTAP 9 Documentation Center