Page: 1
/ 14
Total 203 questions
ServiceNow Certified Implementation Specialist - Data Foundations (CMDB and CSDM) CIS-DF Exam Questions
Question 1
(Choose 2 options)
The following Reconciliation Rules were configured for ServiceNow, Altiris, and SCCM for the Windows Server (cmdb_ci_win_server) class:
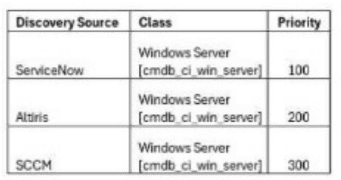
Which statements are true?
Answer : A, C
This question tests understanding of reconciliation source priority in the Identification and Reconciliation Engine (IRE) in ServiceNow.
In reconciliation rules, lower numeric values represent higher priority. Therefore, the priority order is:
ServiceNow (100) -- highest authority
Altiris (200)
SCCM (300) -- lowest authority
Why A is correct
Because Altiris (200) has higher priority than SCCM (300), data from Altiris can update records originally inserted by SCCM. This is exactly how reconciliation precedence works---higher-priority sources can overwrite lower-priority ones.
Why C is correct
SCCM, even though it has the lowest priority, is still an authorized discovery source. It can insert new records into the Windows Server table when no existing CI is identified. Priority only affects updates, not the ability to create records.
Why B is incorrect
ServiceNow (priority 100) can update records from Altiris and SCCM because it has the highest priority. The statement incorrectly claims it cannot.
Why D is incorrect
SCCM does not have the highest authority. A higher numeric value means lower priority, so SCCM cannot update records created by higher-priority sources.
Question 2
What is the value of using the CMDB in security operations? (Choose Two)
Answer : A, D
The CMDB plays a critical role in security operations by providing trusted, structured insight into the organization's IT landscape. When built according to Data Foundations principles---accurate discovery, governed relationships, and alignment to CSDM---the CMDB becomes an essential enabler for security incident response and vulnerability management.
Option D is correct because the CMDB allows security teams to identify exactly which IT infrastructure components are affected by a vulnerability. By correlating vulnerability scan results with configuration items (CIs), security teams can determine whether an issue exists on a server, application, cloud resource, or network device---and understand where that CI sits within the broader service context. This eliminates blind spots and reduces time spent investigating unknown or unmanaged assets.
Option A is also correct because the CMDB supports assessment and remediation activities during security incidents. Once affected CIs are identified, the CMDB provides ownership, support group, environment, and service relationships. This enables security teams to quickly route remediation tasks to the correct resolver groups, assess business impact, and prioritize response based on service criticality. While the CMDB does not perform remediation itself, it enables informed and coordinated action.
Option B is incorrect because vulnerabilities are not auto-resolved by the CMDB; remediation requires human decision-making and execution through security, patching, or change processes. Option C, while related to governance and compliance use cases, is more aligned with GRC and audit functions rather than day-to-day security operations, making it less appropriate for this question.
In summary, the CMDB's primary value in security operations is visibility and actionable insight, enabling faster identification, assessment, and response to security threats.
Question 3
(Choose 2 options)
A CMDB Administrator has built a number of Technology Management Service Offerings (Technical Service Offerings) based on Dynamic CI Groups to better maintain group alignment for the member CIs.
Which groups are synced to CIs from the offering that has a relationship to a Dynamic CI Group?
Answer : B, D
In ServiceNow, Dynamic CI Groups are a core Data Foundations capability used to automatically manage CI membership based on rules rather than manual maintenance. When Technology Management Service Offerings (Technical Service Offerings) are related to Dynamic CI Groups, ServiceNow uses those relationships to synchronize operational support attributes to the member CIs.
The two CI attributes that are intentionally designed to sync in this model are the Managed by Group and the Support Group. These groups directly influence operational ownership and support routing, which is why they are automatically aligned when Dynamic CI Groups are used. This ensures that incidents, changes, problems, and operational tasks are routed consistently as CI membership changes over time.
The Support Group defines who provides day-to-day operational support and is critical for Incident and Request Management workflows. The Managed by Group represents the team responsible for the technical lifecycle and operational health of the CI. Synchronizing these attributes eliminates manual updates and reduces misrouted tickets, which is a key goal of Configuration Management maturity.
The Approval Group (Option A) is not synced because approvals are process-driven and often context-specific rather than CI-driven. Similarly, the Owned by Group (Option C) represents accountability or financial ownership, which is intentionally decoupled from dynamic operational grouping to avoid unintended governance changes.
Therefore, the correct answers are B (Managed by Group) and D (Support Group).
Question 4
A ServiceNow Administrator wants to implement Sen/ice Graph Connectors to provide integrations to many third-party solutions that the company wants integrated into the CMDB
Which categories of connectors are available to the Administrator"?
Answer : A, B
Service Graph Connectors are a key Data Foundations ingestion capability in ServiceNow. They provide out-of-the-box, upgrade-safe integrations that ingest data into the CMDB using the Identification and Reconciliation Engine (IRE), ensuring data quality and source governance.
Two primary categories of Service Graph Connectors are:
Cloud (Option A): These connectors integrate with major cloud providers and platforms (such as AWS, Azure, and GCP) to ingest infrastructure, platform, and service data into the CMDB. They are essential for managing hybrid and multi-cloud environments and maintaining accurate cloud CI relationships.
Observability (Option B): These connectors integrate with monitoring and observability tools (such as APM, infrastructure monitoring, and telemetry platforms). They provide near-real-time operational data that enriches CI records and supports incident correlation, impact analysis, and service health insights.
Option C (DevOps) is incorrect because DevOps integrations are typically handled through CI/CD tools and workflow integrations rather than Service Graph Connectors. Option D (Workflow Automation) is unrelated; Service Graph Connectors focus on data ingestion, not process orchestration.
Therefore, the correct connector categories are Cloud and Observability, making Options A and B the correct answers.
Question 5
What ensures data volume in the CMDB is manageable?
Answer : C
Managing CMDB data volume is a key Data Foundations governance objective. Over time, CMDBs naturally accumulate retired, obsolete, or decommissioned CIs. If these records are not properly managed, they degrade CMDB performance, reduce reporting accuracy, and negatively impact discovery reconciliation and health scores.
Archive Policies are the mechanism designed to address this challenge. They define when CI records should be archived or deleted based on lifecycle state, age, or retention requirements. By automating archival and cleanup, archive policies ensure that only relevant, active CIs remain in the operational CMDB, keeping data volume manageable and performant.
Business Rules (Option A) are used to enforce logic during record creation or updates, not for long-term data volume control. Scheduled Jobs (Option B) may execute tasks, but without archive policies they have no governance logic to determine what should be removed or retained.
Archive policies work in conjunction with CMDB Data Manager to enforce lifecycle-based retention and cleanup, making them the correct and verified answer.
Therefore, Option C -- Archive Policies is correct.
Question 6
An organization is changing data centers and needs to know the consequences of the planned changes.
How can Application Service Mapping be used as part of Change Management?
Answer : B
Application Service Mapping is a critical capability in ServiceNow for enabling business-aware Change Management. Its primary value is not in identifying physical shutdown sequences or CI locations, but in translating technical changes into business impact.
When an organization plans a data center move, multiple infrastructure components---servers, databases, network devices---may be affected. On their own, these technical CIs provide little insight into business risk. Application Service Mapping connects these CIs to Application Services and Business Services as defined by the Common Service Data Model (CSDM). This relationship allows Change Managers to see which business services, customers, and processes are impacted by the planned change.
By leveraging service maps, Change Management can answer critical questions such as:
Which customer-facing services may experience downtime?
What revenue-generating or mission-critical services are at risk?
Which stakeholders must be notified or involved in approvals?
Option A is incorrect because service mapping does not determine shutdown order; that is handled by infrastructure planning. Option C focuses on physical location data, which is typically managed through Location CIs and Discovery, not service mapping.
Therefore, the correct answer is B -- To understand the business impact of CIs, which aligns directly with ITIL 4, CSDM, and Change Management best practices.
Question 7
A CMDB Administrator wants to run the Services Have Owners Identified playbook to remediate the issues shown in the CMDB Data Foundations Dashboard.
Which remediation plays would be used? (Choose two.)
Answer : B, C
In Data Foundations for CMDB and CSDM, a dashboard indicator (like ''Services Have Owners Identified'') highlights a data quality condition---in this case, Services missing required ownership information. The playbook-driven remediation model typically follows a practical sequence: first you identify and validate the scope of the issue, then you correct the underlying records so the metric improves and remains sustainable.
The Analyze Data play is used to break down what the dashboard is reporting into actionable detail. It helps determine which Service records are failing the ownership requirement, what ownership fields are missing (for example, service owner / business owner / technical owner depending on configuration), and where the gaps are concentrated (by business unit, environment, lifecycle stage, or service portfolio segment). This ensures the remediation effort targets the correct records and avoids inaccurate assignments.
The Fix Data play is used to perform the actual remediation---populating or correcting the owner attributes on the Service records so accountability is clear and operational processes can route approvals, escalations, and service decisions correctly. In CSDM terms, clearly assigned owners enable proper stewardship of Service Portfolio and Service Offerings and improve downstream outcomes such as incident assignment accuracy, change impact analysis, and reporting reliability.
While Govern Data supports preventing recurrence (policies, controls, ownership model, and stewardship routines) and Report Data communicates progress, the two plays directly used to remediate the dashboard issue are Analyze Data and Fix Data.