Page: 1
/ 14
Total 196 questions
Splunk Enterprise Certified Admin SPLK-1003 Exam Questions
Question 1
Which of the following statements describe deployment management? (select all that apply)
Answer : A, B
Question 2
In this source definition the MAX_TIMESTAMP_LOOKHEAD is missing. Which value would fit best?

Event example:
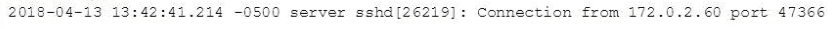
Answer : D
Question 3
The priority of layered Splunk configuration files depends on the file's:
Answer : C
Question 4
Which of the following statements describes how distributed search works?
Answer : C
Question 5
The following stanzas in inputs. conf are currently being used by a deployment client:
[udp: //145.175.118.177:1001
Connection_host = dns
sourcetype = syslog
Which of the following statements is true of data that is received via this input?
Answer : D
Question 6
Which of the following configuration files are used with a universal forwarder? (Choose all that apply.)
Answer : A, C
Question 7
A Universal Forwarder is monitoring a very active syslog stream and as a result is unable to switch between destinations. How would an admin safely remediate this issue?
Answer : C