Page: 1
/ 14
Total 250 questions
UiPath Specialized AI Associate Exam (2023.10) UiPath-SAIAv1 Exam Questions
Question 1
Which filter option should be used for the For Each File in Folder activity to iterate between all the Microsoft Word documents in a local folder?
Answer : A
Comprehensive and Detailed Explanation From Exact Extract:
The correct syntax for filtering both .doc and .docx Word documents is to use the wildcard *.doc*. This matches:
.doc
.docx
Any Word file variant starting with .doc
UiPath Studio uses .NET wildcards for file filters in activities like 'For Each File in Folder'.
UiPath Documentation Reference:
For Each File in Folder -- UiPath Docs
Question 2
What is the recommended split of documents for training and evaluation, considering a total of 15 documents per vendor?
Answer : C
When you create a training dataset for document classification or data extraction, you need to split your documents into two subsets: one for training the model and one for evaluating the model. The training subset is used to teach the model how to recognize the patterns and features of your document types and fields. The evaluation subset is used to measure the performance and accuracy of the model on unseen data.The evaluation subset should not be used for training, as this would bias the model and overfit it to the data1.
The recommended split of documents for training and evaluation depends on the size and diversity of your data. However, a general guideline is to use a 70/30 or 80/20 ratio, where 70% or 80% of the documents are used for training and 30% or 20% are used for evaluation. This ensures that the model has enough data to learn from and enough data to test on. For example, if you have 15 documents per vendor, you can use 10 documents for training and 5 documents for evaluation. This would give you a 67/33 split, which is close to the 70/30 ratio.You can also use the Data Manager tool to create and manage your training and evaluation datasets2.
Question 3
What is the purpose of the One Click Classification feature in the UiPath Document Understanding interface?
Answer : A
Comprehensive and Detailed Explanation From Exact Extract:
One Click Classification streamlines the training process by eliminating the need to manually create AI Center components like datasets and pipelines. It enables users to train custom document classification models entirely within the Document Understanding interface in Studio or Orchestrator.
This feature is especially helpful for business users or developers new to AI Center.
UiPath Documentation Reference:
One Click Training -- Document Understanding
Question 4
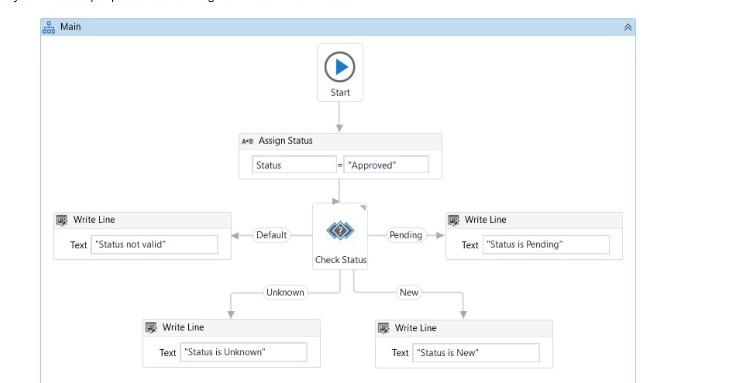
What will be displayed in the Output panel after running the workflow below?
Answer : A
From the provided workflow:
The Assign Status activity sets the variable Status to the value 'Approved'.
The Check Status activity evaluates the value of Status against defined conditions.
It has branches for 'Pending', 'New', and 'Unknown'.
The 'Default' branch is triggered if none of these conditions match the value of Status.
Since 'Approved' does not match 'Pending', 'New', or 'Unknown', the Default branch will execute.
The Write Line activity in the Default branch outputs 'Status not valid.' to the Output panel.
Question 5
Where should a model be pinned in UiPath Communications Mining?
Answer : C
According to UiPath documentation, model versions can be pinned and managed on the 'models' tab, ensuring that users can maintain and revert to specific versions when necessary for continuity and performance
Question 6
What are the out-of-the-box packages types available in Al Center?
Answer : B
UiPath AI Center offers three primary package types: pre-trained, custom training, and fine-tunable models. These are essential for various use cases, from leveraging existing models to training custom ones based on specific data
Question 7
Which of the following is true when creating an ML Package in UiPath Al Center?
Answer : A
When creating an ML Package in UiPath AI Center, the package name must adhere to Python naming conventions, meaning it cannot include reserved keywords such as class, break, finally, etc. This ensures that the package can be successfully deployed without conflicts in the Python environment.